

Aegis Softtech Java development team is sharing this post with global developers who want to learn how to implement Kinesis technology and cloud computing to achieve modern streaming of data. You may proceed and read this article further to learn basics and specialized code for Kinesis implementation.
What is the Cloud?
The term Cloud does not refer to the clouds in the sky. In the words of Wikipedia, it means 'Cloud computing involves deploying groups of remote servers and software networks that allow centralized data storage and online access to computer services or resources'. I personally have a different version of it.
It is a term specifically used in the Tech industry which means that anything and everything can reside centrally and be shared without having to worry about the local storage or even local computing powers. Consider the case wherein a product that is developed has to be deployed for people to access it. The normal algorithm would be to buy huge servers and database space, deploy the application and pay for the usage of the services. Most of the time, the servers are being unused, the processing power wasted, the database disk not fully utilizing its true potential.
This results in the monetary loss of the company developing the products as well as a waste of technological resources. To address such situations and others, all of them quite grave, the concept of 'Cloud Computing' came into existence which aimed at sharing the resources centrally and thereby achieving a win-win situation. There are 3 ways which define the sharing of resources:
- 1. Infrastructure as a service (IaaS): IaaS is a type of cloud computing in which a third-party provider hosts virtualized computing resources over the Internet.
- 2. Platform as a service(PaaS): PaaS is a cloud model in which providers deliver apps over the Internet and host users' hardware and software on their infrastructure.
- 3. Software as a Service (SaaS): SaaS is a software distribution model in which applications are hosted by a vendor or service provider and made available to customers over a network, typically the Internet.
What is the Amazon Web Services?
Amazon Web Services (AWS) is another name for Cloud in whatever manner it is defined. AWS comes with a bunch of services, all of them catering to the cloud model, that allows any application to use the powerful advantages that the Cloud model suggests. Starting from sharing of the processing power, to the database, to the security system, to the sharing of computer hardware, it is a one-stop-shop for any cloud requiring application. The screenshot lists all the components of AWS:

Kinesis – The road to modern streaming of data
The origin of the word 'Kinesis' is largely attributed to the word 'Kinetic' in Physics. It means, something which is moving or is in motion. Much the same way, Kinesis is a technology offered by the aws cloud analytics that aids when there is a requirement to continuously move data directly from one end to the other end. It offers a platform wherein data produced by one end is immediately shipped (moved) to the other end with minimal configuration.
And this requires implementation of Kinesis technology and cloud computing. Visit us to acquire more information on the implementation of the technology.
AWS in general offers an API to work with in a variety of languages, such as .NET, PHP, Java etc. Each of them provides with the necessary SDK to perform any and every operation on any service in AWS. We are going to provide the code snippets of different Kinesis operations for Java, since we have extensively worked for Java Development with AWS. The pre-requisites for operating as under would be a JAVA SDK and Maven installed on the machine.
How to use Amazon Kinesis?
To use AWS Kinesis, or as a matter of fact, any AWS Services, one must download the awssdk to use its features. Specifically for Kinesis, one must also download an additional library that helps in the development of a Consumer (one that received the data) in a much easier fashion. In case of Maven usage, the following snippets of code are used to download the sdk. If Maven is not present, one can manually download the aws-java-sdk from the Internet.
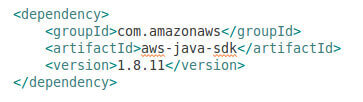
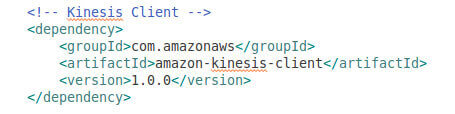
The versions can be changed to suit the needs.
Amazon Kinesis Architecture
Before proceeding further it would be nice to understand some technical jargon associated with Kinesis:
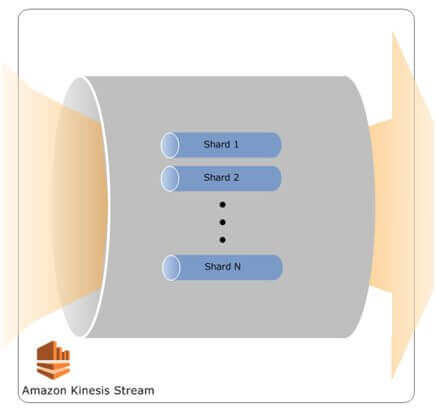
- 1. Stream – A stream represents an ordered sequence of data records. The data records in a stream are distributed into shards.
- 2. Shards – Internally, each stream stores its data in shards. The number of shards that each stream will have is a volatile variable. It depends on the fact that at what rate the producer is producing data and at what rate will the Consumer consume data. Each shard can read at 2MB/s or max. 5 transactions per second and write at 1MB/s or a maximum of 1000 writes per second. The image below shows the internal structure of a stream
- 3. Producer – One who sends (produces) the data to Kinesis. For example, a web server sending analytics data to a stream is a producer.
- 4. Consumer – One who receives (consumes) data from Kinesis
- 5. Partition Key - A partition key is used to group data by shard within a stream. Partition keys are Unicode strings with a maximum length limit of 256 bytes. An MD5 hash function is used to map partition keys to 128-bit integer values and to map associated data records to shards.
- 6. Sequence Number - Each data record has a unique sequence number. It is the responsibility of the producer to assign each data record a unique sequence number whilst it is adding data to the stream.
- 7. Application Name – Each Kinesis application is identified by a unique application name. The application must have a unique name across the Amazon account and region used by the application.
- 1. A Normal Consumer: A normal consumer is built using the basic amazon sdk. It requires a lot of overhead to be handled manually like, when a shard is split (resulting in 2 shards from 1 and hence double the stream capacity) or merged (resulting in 1 shard from 2 and hence half the stream capacity), the code has to handle these transitions and fetch the data accordingly. Likewise, in case of stopping the code and reading data again later, the Consumer has to keep track of how much data has been read previously, and hence read from that point.
- 2. KCL Consumer: KCL is a library offered by Amazon, that handles all the heavy chores such as the one mentioned above, and directly offers a channel that reads the data from the stream and presents it to the user for further manipulation. The second entry of the library above is specifically for KCL and is not a part of awssdk.
Kinesis API:
Following are the most important Kinesis API calls that are used very frequently and are the ones that we have been using in our projects.
- 1. CreateStream: This is the API call that is used to create a stream in an aws account in a particular region.

One has to specify the region when creating the stream. AWS, with all of its services, is distributed in many different regions around the globe. The region is specified as follows:
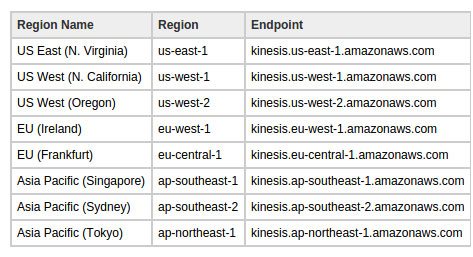
The endpoint can be one of the many values as defined below:

- 2. DescribeStream: This is the API call used to check on the stream. It is used to describe the stream in terms of whether it is Active or not, how many shards are there, when was it last modified, etc.

'KinesisClient' is a variable that has been initialized as an establishment to AWS Kinesis
- 3. PutRecords: This API call is used by the Producer while adding data to the stream in Kinesis.

One has to set the partition key while adding data to the producer. It is necessary for the Producer to add the data wrapped in a ByteBuffer because that is how Kinesis accepts the data.
- 4. Using ShardIterator to retrieve records: This is the conventional approach of fetching data from the Stream. It is not recommended to use this approach anymore since there is a more efficient approach i.e., KCL


- 6. MergeShard: This operation is used, when the Producer is producing less data than the capacity of the total number of shards. In such a case, the situation is such that the operation will not be affected even when there is 1 shard lesser in the stream. This is primarily done to reduce the costs, because the cost of a stream is associated to the number of shards in it.
- 7. SplitShard: This operation is used, when the Producer is producing more data than the capacity of the total number of shards. In such a case, the situation is such that if not done anything, Kinesis will not be able to ingest all the data that is being produced by the Producer because the capacity of the stream is less than the capacity of producer producing data. A split shard will result in an increase in cost, because the cost of a stream is associated to the number of shards in it.
- 8. KCL: This is the most efficient approach to read data from Kinesis stream, since the library handles all the heavy tasks in the backend and leaves the user with the data.
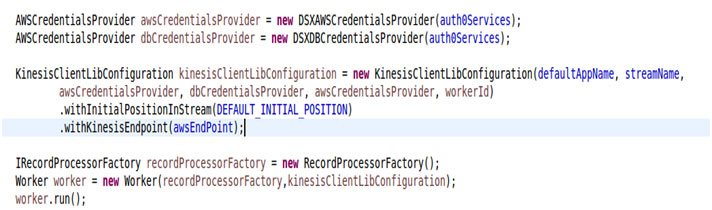
The appName is the tableName that is created in DynamoDB for checkpointing purposes. The intial position is a variable which tells KCL from where to start reading the data in the stream. It can have one of the two values as under:
- a. LATEST – Start reading the Latest data in the Stream
- b. TRIM_HORIZON - Start reading from the beginning of the Stream
The key component in KCL is the Record processor. One has to implement the RecordProcessor.java which extends RecordProcessorFactory class. The key methods to be implemented are:
- 1. initialize: This method is used for any intialization required
- 2. processRecords: This is the key method which is responsible for delivering the data
- 3. checkpoint: This method is used by KCL for checkpointing how much data is read previously. The checkpointing is done in AWS DynamoDB, again an AWS Service.
- 9. DeleteStream: This API call is used to delete a stream from a particular region from AWS Kinesis

Conclusion
The team is glad to share this post with global developers and let them learn about implementation of Kinesis and cloud for modern streaming of data. Don’t forget to feedback us and making queries related to java development
For further information, mail us at [email protected]
