Here Hadoop development experts will make you understand the concept of multiple input files required in Hadoop MapReduce. As a mapper extracts its input from the input file, if there are multiple input files, developers will require the same amount of mapper to read records from input files. In this story, professionals are making use of two input files with two mapper classes and a reducer. Read the complete story to know more.
We are introducing multiple input files in Hadoop MapReduce.
Consider a simple hypothetical case where you want to load the data from various different data sources having different format/separators.
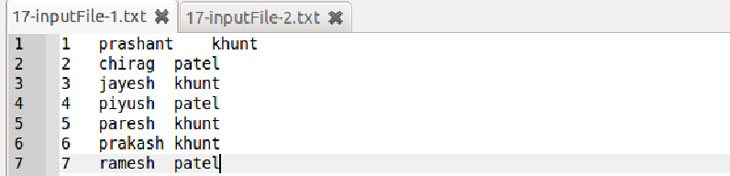
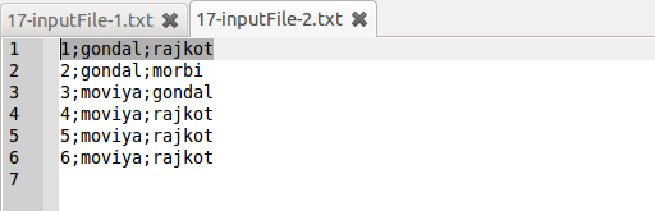
For the above simple case we are assuming that we do have 2 different files of users with different records. The files also have different separators.
Now, to solve this type of problem we can use Multiple Inputs from hadoop.
How to solve this problem?
To solve this type of problem we can take below approach,
- Use 2 different mappers for individually parsing the records from different files (with different formats).
- Use 1 reducer, so that we can also join the record's values.
- Writing the records to HDFS at the end of joining.
This is also an example of Reducer side join in hadoop mapreduce.
If you are facing problems in merging data from different data sources that have different format and separators, then visit us.
Our expert team will solve the issue using multiple input files.
Though the solution is a left outer join, you can tweak this code to perform any type of join as you wish.
Environment:
Java : 1.7.0_75
Hadoop : 1.0.4
Sample Input Files:
Sample input file 1 (TAB separated file)
Sample input file 2 (“;”separated file)
I used the below code to solve this problem.
MultipleInputMapper1.java
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MultipleInputMapper1 extends Mapper<LongWritable, Text, LongWritable, Text<
{
private static String separator;
private static String commonSeparator;
private static String FILE_TAG="F1";
public void setup(Context context)
{
Configuration configuration = context.getConfiguration();
//Retrieving the file separator from context for file1.
separator = configuration.get("Separator.File1");
//Retrieving the file separator from context for writing the data to reducer.
commonSeparator=configuration.get("Separator.Common");
}
@Override
public void map(LongWritable rowKey, Text value,
Context context) throws IOException, InterruptedException
{
String[] values = value.toString().split(separator);
StringBuilder stringBuilder = new StringBuilder();
for(int index=1;index<values.length;index++)
{
stringBuilder.append(values[index]+commonSeparator);
}
if(values[0] != null && !"NULL".equalsIgnoreCase(values[0]))
{
context.write(new LongWritable(Long.parseLong(values[0])), new Text(FILE_TAG+commonSeparator+stringBuilder.toString()));
}
}
}
MultipleInputMapper2.java
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MultipleInputMapper2 extends Mapper <LongWritable, Text, LongWritable, Text>
{
private static String separator;
private static String commonSeparator;
private static String FILE_TAG="F2";
public void setup(Context context)
{
Configuration configuration = context.getConfiguration();
//Retrieving the file separator from context for file2.
separator = configuration.get("Separator.File2");
//Retrieving the file separator from context for writing the data to reducer.
commonSeparator=configuration.get("Separator.Common");
}
@Override
public void map(LongWritable rowKey, Text value,
Context context) throws IOException, InterruptedException
{
String[] values = value.toString().split(separator);
StringBuilder stringBuilder = new StringBuilder();
for(int index=1;index&lt;values.length;index++)
{
stringBuilder.append(values[index]+commonSeparator);
}
if(values[0] != null && !"NULL".equalsIgnoreCase(values[0]))
{
context.write(new LongWritable(Long.parseLong(values[0])), new Text(FILE_TAG+commonSeparator+stringBuilder.toString()));
}
}
}
MultipleInputDriver.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MultipleInputDriver extends Configured implements Tool
{
@Override
public int run(String[] args) throws Exception
{
int status = -1;
Configuration configuration = getConf();
//Setting the Separator for parsing TAB separated input file 1 for MultipleInputMapper1
configuration.set("Separator.File1", "\t");
//Setting the separator for parsing ";" separated input file 2 for MultipleInputMapper2
configuration.set("Separator.File2", ";");
//Setting the separator for Reducer for saving the file into TAB separated output file.
configuration.set("Separator.Common", "\t");
Job job = new Job(configuration, "Multiple Input Example");
//TAB separated input File 1
MultipleInputs.addInputPath(job,new Path(args[0]), TextInputFormat.class, MultipleInputMapper1.class);
//";" separated input file 2
MultipleInputs.addInputPath(job, new Path(args[1]), TextInputFormat.class, MultipleInputMapper2.class);
job.setJarByClass(MultipleInputDriver.class);
job.setReducerClass(MultipleInputReducer.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job, new Path(args[2]));
job.waitForCompletion(true);
status = job.isSuccessful()? 0:-1;
return status;
}
public static void main(String [] args)
{
int result;
try{
result= ToolRunner.run(new Configuration(), new MultipleInputDriver(), args);
if(0 == result)
{
System.out.println("Job completed Successfully...");
}
else
{
System.out.println("Job Failed...");
}
}
catch(Exception exception)
{
exception.printStackTrace();
}
}
}
MultipleInputReducer.java
import java.io.IOException;
import java.util.Arrays;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MultipleInputReducer extends Reducer<LongWritable, Text, LongWritable, Text>
{
private static String commonSeparator;
public void setup(Context context)
{
Configuration configuration = context.getConfiguration();
//Retrieving the common file separator from context for output file.
commonSeparator=configuration.get("Separator.Common");
}
@Override
public void reduce(LongWritable key, Iterable<Text>
textValues, Context context) throws IOException, InterruptedException
{
StringBuilder stringBuilder = new StringBuilder();
String[] firstFileValues=null, secondFileValues=null;
String[] stringValues;
for (Text textValue : textValues)
{
stringValues = textValue.toString().split(commonSeparator);
if("F1".equalsIgnoreCase(stringValues[0]))
{
// firstFileValues = stringValues;
firstFileValues=Arrays.copyOf(stringValues, stringValues.length);
}
if("F2".equalsIgnoreCase(stringValues[0]))
{
secondFileValues = Arrays.copyOf(stringValues, stringValues.length);
}
}
if(firstFileValues != null)
{
for(int index=1;index&lt;firstFileValues.length;index++)
{
stringBuilder.append(firstFileValues[index]+commonSeparator);
}
}
if(secondFileValues != null)
{
for(int index=1;index&lt;secondFileValues.length;index++)
{
stringBuilder.append(secondFileValues[index]+commonSeparator);
}
}
context.write(key, new Text(stringBuilder.toString()));
}
}
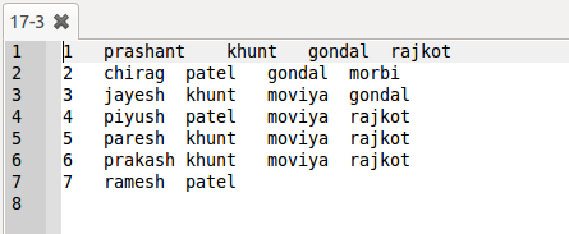
After running the code, the output file looks like,
In this case, we can see that the record 7 is having values in File 1 only while there is no value for record 7 in file 2 hence it performs a left join.
Code Walk Through:
- Most of the code is self-explanatory, so you can easily check and get line by line understanding of the code.
And it’s done. You can start using multiple input files in MapReduce as per the need.
Conclusion
Hadoop development experts are here to help you out on your custom software development solutions. Just mention the problem you are facing while using them in the comments and experts will answer it soon.
I hope this program will help you to understand Multiple inputs and left join in hadoop mapreduce.
For further information, mail us at [email protected]