

Data science, an interdisciplinary field, uses scientific systems, algorithms, processes, and other methods to gain insight and knowledge from data in different forms, both unstructured and structured. It is a lot like data mining. The concept of data science is to help unify statistics, machine learning, data analytics services, and other related methods. Additionally, a Java development company can play a crucial role in implementing these data science techniques by providing robust and scalable software solutions.
That way, people will better understand and analyze information with data. It uses different theories and techniques that are drawn from various fields within the context of computer science, information science, statistics, and mathematics.
Want to Accelerate your career in Machine Learning?
Demand for Machine learning development and consulting services has been increasing in the past years as companies are discovering new methods for solving their problems using meaningful data.
Data science became a buzzword when the Harvard Business Review called it “The Sexiest Job of the 21st Century,” it became a buzzword. Because of this, it tends to be used to describe predictive modeling, business intelligence, business analytics, or other uses of data, or to make statistics sound more interesting. We’re going to make sure that you learn what real data science is so that you can reap the real benefits.
Data science has popped in lots of different contexts over the past 30 years or so, but it didn’t become established until quite recently. Peter Naur used it to describe computer science in the ‘60s. Naur later started using the term datalogy. Naur then published the Concise Survey of Computer Methods in 1974. It referenced data science freely in the way it looked at the standard data processing methods that were used in different ways.
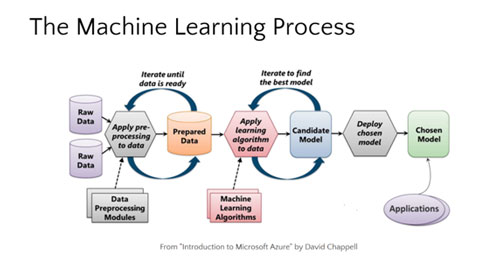
What is it? Exactly?
At the core of data, science is Data. There are troves of raw information that is being streamed in and then stored in data warehouses. There is a lot to learn through mining it. There are advanced capabilities that can be built from it. This means that data science services India using data in creative ways to add business value. It flows like this:
- Data Warehouse Discovery of Data - Insight and quantitative analysis to help strategic business decision making.
- Data Product Development - algorithmic solutions in production and operating.
- Business Value
How does Machine Learning work under the hood?
Through this Learning process, we will be learning about:
- 1. Learn how to frame a Problem Statement for Machine Learning
- 2. Fundamental terminologies and operation of machine learning
- 3. Development of Data Sets
- 4. Data Collection and Data Preparation using data sets
- 5. Understanding of robust data Visualizations and Feature engineering
- 6. Using Model Training and evaluation process
- 7. Goal Evaluation in Business
- 8. Prediction using Machine Learning
Are you excited to gain knowledge in the Machine Learning Path?
In the World of Data Science and Artificial Intelligence with Big Data and Cloud Computing, we will bring to you the latest ecosystem where you will have up-to-date knowledge. Mastering Machine Learning is hard until and unless you are learning it yourself. If you need help along the way, an apa paper writing service can assist in breaking down complex topics into manageable insights. Feature Engineering has a lot of importance and impact when you are preparing models.
Visit us as we are specialised in this interdisciplinary field and train our candidates to make use of their knowledge in building their career.
Step 1: Defining your Problem Statement
Do you know what Data is?
- Data is the raw form of resources which we collect from various methods. Solving business problems is the goal of a data scientist, and a lot of activities are involved.
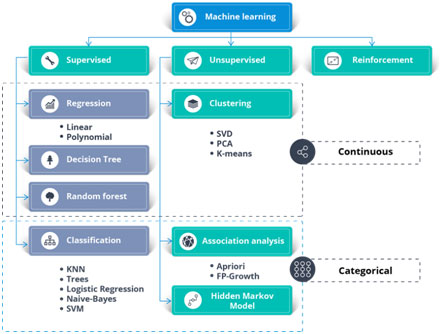
- Data Science Consists of Data Mining Activities, Machine Learning, AI, Deep Learning, Python/R, Statistical, and Analytical Skills.
-
Data Analysis includes Business Intelligence, reporting with Excel/Tableau/ PowerBI, Hadoop based analytics.

- Data mining techniques can be potent, and the need to detect and avoid overfitting is one of the most important concepts to grasp when applying data mining to real problems.
- The idea of overfitting and its avoidance permeates data science processes, algorithms, and evaluation methods.
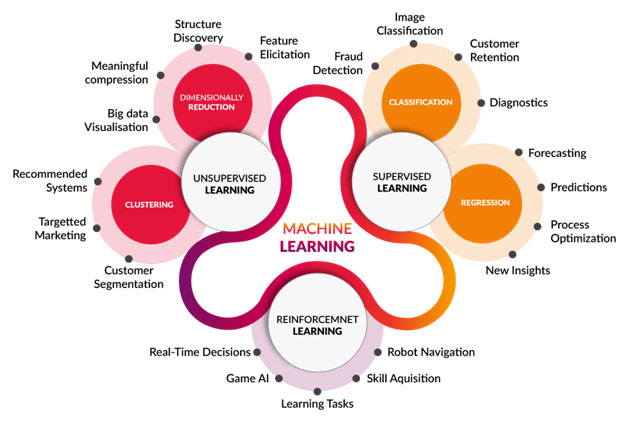
When do you use Machine Learning?
From Analyzing Cancer to movie prediction machine learning has given computer systems a lot of new abilities.
We’ve been asked to create an automated system which predicts which item in the restaurant gets sold first. The System which automates this process is called a “Model,” and the model is structured using the method of “Training.” To create an Accurate model, we have to ask questions about the data, and hence, we have to collect data.
How do you get started?
Business vs ML Problem
Learn How to think about machine learning and start applying machine learning in your path
To Use the Systematic Approach, start with picking up a Tool
- Weka
- Python
- R
- Any Machine Learning Programming Language
Start Practicing on Datasets where the problem matters to you. After you have done with the execution, start building a portfolio.
Step 2: Data Collection, Data Preparation
Do you know how to Prepare Data? Want to know how to build accurate models?
Having known the basics of Python will help you leverage machine learning. A related application to Search Engine Optimization is Collaborative Filtering. Internet bookstores such as Amazon, or video rental sites such as Netflix use this information extensively to entice users to purchase additional goods.
Data Normalization is the process where the analysts and scientists convert their unstructured data into the meaningful form and gather insights from the data. These insights are collected after the data preparation, where all the missing and incomplete data are cleared.
Minimizing an arbitrary function is, in general, very difficult, but if the objective function to be reduced is convex then things become considerably simpler. In many modern applications, data is available only in a streaming fashion, and one needs to predict labels on the fly.
Step 3: Data Models and Comparison of Machine Learning Algorithms
Evaluating a classifier is often significantly trickier than assessing a regressor so that we will spend a large part of this chapter on this topic.
Cross-Validation
Implementing Cross-Validation Occasionally you will need more control over the cross-validation process than what cross_val_score () and similar functions provide.
Confusion Matrix
Confusion Matrix is compared as a better way to check the performance of a classifier. For example, to know the number of times the classifier confused images of 5s with 3s, you would look in the 5th row and 3rd column of the confusion matrix.
Error Analysis
Trying out multiple models, shortlisting the best ones and fine-tuning their hyperparameters using GridSearchCV, and automating as much as possible.
Step 4: Optimizing your Machine Learning Algorithm for Better Results
Machine Learning Algorithms can be optimized using Ensemble Methods.
Boosting (originally called hypothesis boosting) refers to any Ensemble method that can combine several weak learners into an active learner. There are many advancing methods available, but by far the most popular is AdaBoost.
One way to get a diverse set of classifiers is to use very different training algorithms, as just discussed. Another approach is to use the same training algorithm for every predictor but to train them on different random subsets of the training set.
Another viral Boosting algorithm is Gradient Boosting. Just like AdaBoost, Gradient Boosting works by sequentially adding predictors to an ensemble, each one correcting its predecessor.
However, instead of tweaking the instance weights at every iteration as AdaBoost does, this method tries to fit the new predictor to the residual errors made by the previous predictor.
Step 5: Machine Learning Model Production
One problem with the other implementation of PCA is that it requires the whole training set to fit in memory for the SVD algorithm to run. A Machine Learning course can help mitigate this issue by teaching alternative methods and optimizations for handling large datasets, ensuring you stay updated with the most effective techniques in the field. Machine Learning is a Field where the learning never ceases, and you must keep gaining knowledge to be equipped with the most in-demand skills in the domain.
When you are growing a tree in a Random Forest, at each node only a random subset of the features is considered for splitting. Starting the journey is a pretty tough task, but once you have gained in experience, there will be no reason to stop learning.
What’s Next?
In Short with Links
1) First Month
Week 2 (Calculus)
Week 3 (Probability)
https://www.edx.org/course/introduction-probability-science-mitx-6-041x-2
Week 4 (Algorithms)
https://www.edx.org/course/algorithm-design-analysis-pennx-sd3x
2) Second Month
Week 1
Learn Python for data science
Math of Intelligence
Intro to Tensorflow
Week 2
Intro to ML (Udacity) https://eu.udacity.com/course/intro-to-machine-learning--ud120
Week 3-4
ML Project Ideas https://github.com/NirantK/awesome-project-ideas
3) Third Month (Deep Learning)
Week 1
Intro to Deep Learning
Week 2
Deep Learning by Fast.AI http://course.fast.ai/
Week 3-4
Re-implement DL projects from my GitHub https://github.com/llSourcell?tab=repositories

