DevOps is a bunch of programming advancement practices that consolidate Software Development (Dev) and Information Technology Operations (Ops). In this blog we will be using the tool Ansible - IT configuration and Deployment Tool to automate a Hadoop cluster.

What is Hadoop?
Hadoop is an assortment of open-source programming utilities that utilizing numerous computers associated through a network takes care of the issues involving huge information and computation. It goes under Apache Software Foundation.
What issue do we solve by automating Hadoop?
With the advancement in technology, time is becoming a major issue. Several things are done manually which takes time. In today’s era, almost all companies are facing the problem to store and process their large amount of data. Suppose a new system comes into the industry, we have to deploy all the codes according to our needs that already exists in the industry and which takes a lot of time to do all the changes. These things can be now done through automation.
Why do we need to automate Hadoop?
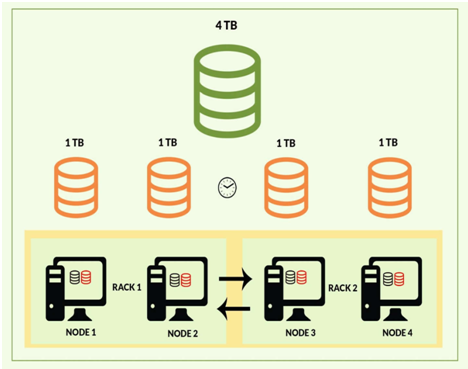
Deploying an infrastructure grade Hadoop cluster is a monumental task and can take a lot of time to deploy as every system needs to be configured for its specific purposes like data nodes for storage, nodes for job scheduling and processing, etc. Our expert big data hadoop developer will implement HDFS that is mainly used for data storage.
Hadoop Architecture
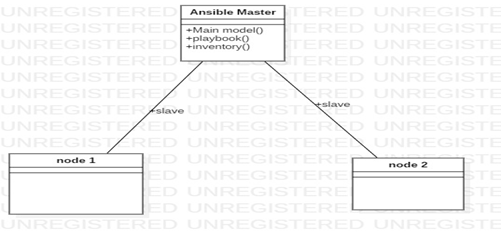
Ansible Architectural Diagram:
The software and hardware requirements of this project are as follows:
| Sr. No. | SOFTWARE | HARDWARE |
|---|---|---|
| 1. | RHEL 7.5 and above | A minimum of 1 GHz processor |
| 2. | YML, JINJA | A minimum of 1 GB RAM |
| 3. | Ansible, HTTP, Hadoop | No strict specifications about hard disk |
METHODOLOGY
Hadoop:
The primary infrastructure software services aimed to automate are as follows:
Step 1: Install the ansible package in Linux using yum. In this, we are installing an ansible package using the “yum install ansible” command. Before this, yum is to be configured.
Step 2: Then make Ansible galaxy of Hadoop Cluster in some different folders like playbooks. This Hadoop cluster is implemented to solve the big data problem using the command “Ansible-galaxy init hadoop cluster”.
Step 3: Accordingly put the client IP in the host’s file so that it can read the IP from there and so that playbook can be automatically run in that system. The location of a host file would be “/etc/ansible/hosts”.
Step 4: Configure the ansible file according to the need in ansible.cfg file.
Step 5: Write a Hadoop cluster role to set-up a Master Node, Slave Node.
Step 6: Then create a site.yml file in which write a code to import the role Hadoop.
Step 7: Execute the file using the command “ansible-playbook site.yml”.
Step 8: In the Client node role: we copy the Java and Hadoop setup files to the respective nodes.
Step 9: In the Master node role: we copy the master node configuration ie core-site.xml and hdfs-site.xml on the master node machine.
Step 10: In the Slave node role: we copy the slave-node configuration ie core-site.xml and hdfs-site.xml on the master node machine.
Step 11: Now we have to run the following command:
On Name Node - “hadoop-daemon.sh start namenode”
On Data Node -“hadoop-daemon.sh start datanode”
Step 12: On the client, the machine checks the Hadoop setup by running the following command:
“hadoop hdfs admin -report”
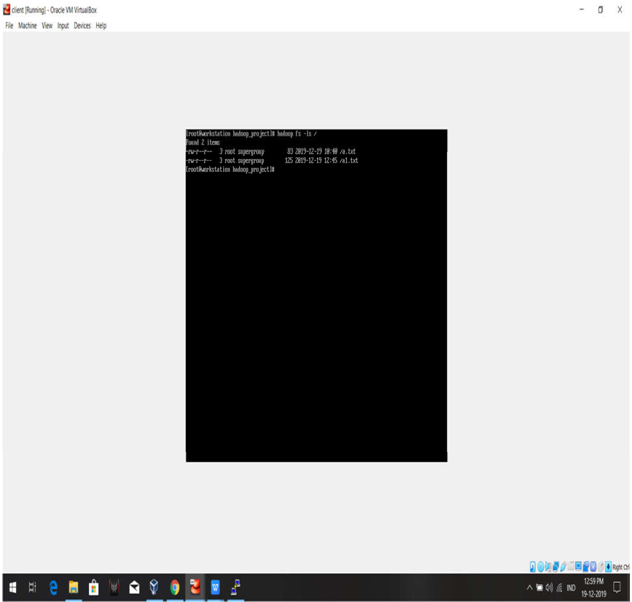
Step 13: To upload a file using the command: “ hadoop fs -put filename / ”
Step 14: To upload a file using the command: “ hadoop fs cat /filename ”
All the respective yml files are listed below:
NOTE: STRICT IDENTATIONS ARE TO BE USED
Site.yml
Inventory
Client role: main.yml
Master Node: main.yml
Core-Site.xml
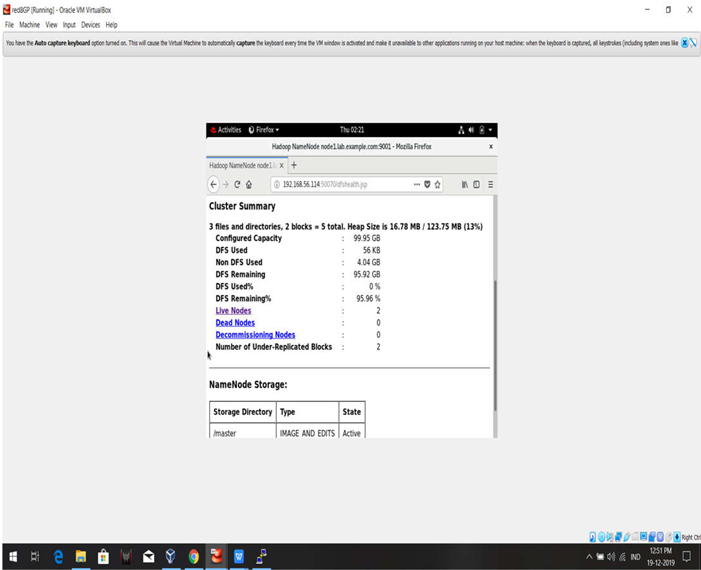
SCREENSHOTS:
HADOOP
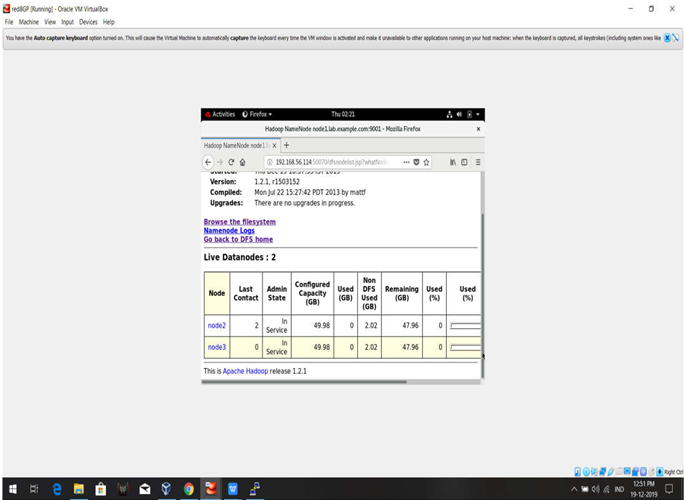
CLUSTERS SUMMARY
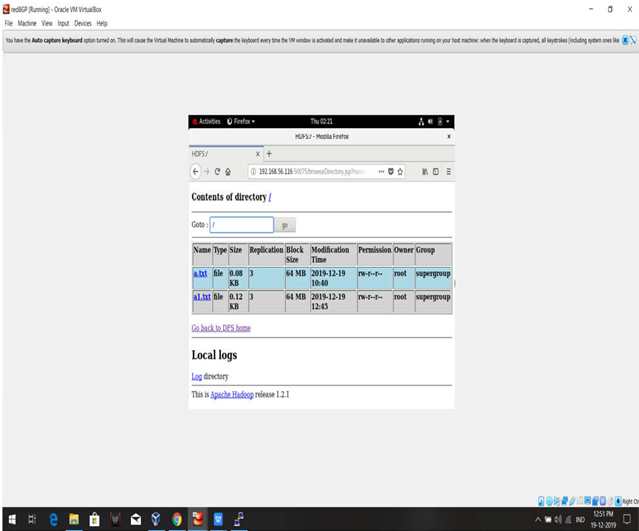
FILE UPLOADS