

Setting up and implementing Hadoop services in a cost effective way in near to impossible for small and medium sized organizations. Large scale data driven companies and various Hadoop professional services providers can make optimum utilization of Hadoop. There are generally four modules in Hadoop- Distributed file system, Hadoop common, MapReduce, and YARN.
Distributed file system permits data storage in an easy-to-access format throughout numerous connected storage devices. In MapReduce module, the data is read from the database, put into a suitable analysis format that called as Map, and perform various calculations, i.e. count total males over 30 years of age in the database (reduce). Hadoop common offers advance Java Tools for Developers, which are used for reading data. YARN handles resources of the data storing systems and analysis operations.
Get expert developers, get results. Free quote today!
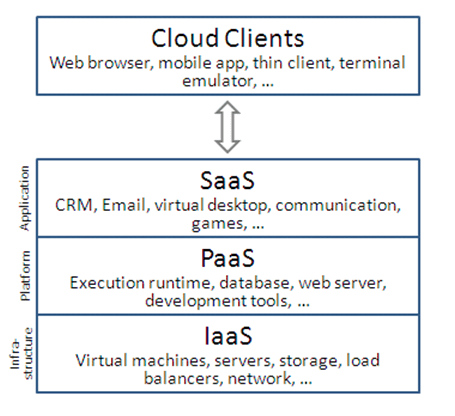
Subsequently, Hadoop as a service (HAAS) offering ensures a managed Hadoop cluster that is ready to use with no configuration requirement or installation of other Hadoop related services on any node, such as Jobtracker, Namenode, Datanode, Tasktracker, and may offer secondary services such as Hbase or Zookeeper. There are pre-installed tools available in Hadoop services like Pig, Hive and Sqoop.
HAAS can be located in the cloud on the basis of service level, abstraction, and tools of Hadoop services.
Hadoop users and clients need not to worry about configuring Hadoop services; it is managed by the Hadoop professionals. They manage all software versions, starting or pausing cluster and stability professionally. This eliminates the operational burden for companies and makes Hadoop services efficient to use.
General designs and usage patterns with Hadoop services are employing clusters for common Big Data processing requirements, which could be consistent or temporary. The most highlighted advantage of hadoop services is the cost; the client only pay for particular service he used.
For further information, mail us at [email protected]

