


Big data world comes with big challenges and even more challenging is tuning the Big data world comes with big challenges and even more challenging is tuning the big data development services for optimal performance. Apache Spark is a fast parallel processing framework but bad design elements or bad configuration could take away the powers of this strong framework. In this article, we will look into various things that should be consider before working with spark.
Partition is the logical division of data distributed across various nodes in a cluster. By default, spark automatically creates a partition for each HDFS block (~64MB). Although, we can change the size and number of partitions based on our application but having too many partitions could result in small partitions with no data or less data and having too few partitions could result in under-utilized resources thus affecting the performance adversely.
If we have 20 cores in our cluster, then recommended tasks/partitions per core is 2-3. One way to change the number of partitions is by passing the second argument to spark transformations. For example,

Another way to change the number of partitions is changing the below spark property,
which controls the parallelism and defaults to 8
Small file problem:
Smaller files are usually smaller than HDFS block size; such small files result in small partitions thus degrading application efficiency. One way to fix small file problems is to compress these files into gzip/lzo compression.
However, it introduces another set of performance problems such as uncompressing and unsplittable files. Another way is to use coalesce () method to decrease the number of partitions.
Compressed files
Compressed file formats such as gzip are unsplittable formats that form a single partition and thus bypassing the whole concept of parallelism since a single partition executes only in a single executor. One way to tackle gzip-compressed files is to repartitions the rdd to run on multiple executors using the repartition () method but remember it will cause the whole data to reshuffle across the network.
Second way to tackle this problem is to use splittable compressed file formats like lzo.

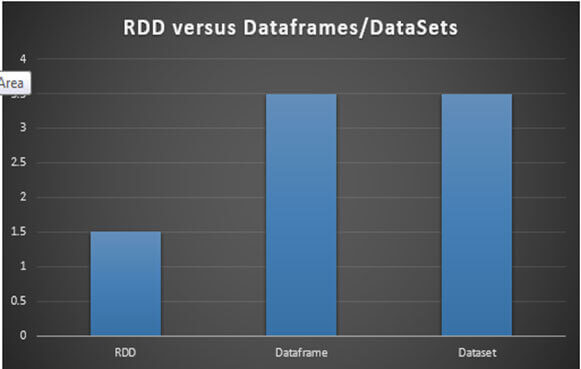
Dataframes and Datasets are built atop Catalyst optimizer and Tungsten contributing to their higher performance than RDD. Tungsten provides the performance by rewriting spark operations in bytecode at runtime and catalyst provides performance by optimizing queries written in spark sql and dataframe dsl.
Therefore, choosing the dataframes/datasets over RDD can improve the overall runtime of application especially when you have semi-structured data (on which you could impose some structure). Even further, Datasets comes with best from both the world; it has type safety as well as optimizing power of both Catalyst optimizer and Tungsten under the hood.
Avoid Linked data structures as far as possible such as HashMap and LinkedList because they consist of object header (16 bytes) and pointers to the next object (8 bytes each) resulting in much heavier data structure to transfer over the network. Instead, use simpler data structures such as arrays of objects.
You can also set the JVM flag -XX: +UseCompressedOops in spark-env.sh to make pointers 4-bytes instead of 8-bytes.

Java String comes with extra overhead of 40 bytes for each string object along with 2 bytes for each character. Therefore, a 4-character string will actually end in 48 bytes. Instead of using Strings as keys, use numeric or enumerations.
Avoid shuffling at all cost since it causes redistribution of data across partitions thus degrading performance. Few of the spark API cause full shuffling and can be replaced with other spark API that does not involve full shuffling. For example,
The reduceByKey could be used instead of groupByKey because groupByKey shuffles all the data but reduceByKey shuffles only the result of aggregated data.
Coalesce faster than repartition
If your sole purpose is to decrease the number of partitions, then coalesce may run faster than repartition because coalesce reuses existing partitions to minimize the amount of data that is shuffled whereas repartition does a full shuffle to redistribute data across partitions.

Kryo serialization is often 10X faster than Java serialization but the only drawback of Kryo Serialization is that it does not provide support for all serializable types. By default, spark use java serialization but you can switch to Kyro by setting the spark configuration:
You can also register your own class with Kyro by registerKyroClass with spark configuration.
Spark has two types of memory viz. execution space - used for computation purposes, storage space - used for caching purposes. Both of these memories share a unified space and can acquire each other space if required.

For example, if your application is computation intensive, execution memory can take up the storage space whereas if your application is memory-intensive, storage memory can span over the execution storage space.
spark.memory.fraction: Unified memory space reserved for both execution and storage memory. Default value is 60% of JVM heap space.
spark.memory.storageFraction: Represents the fraction of unified memory for saving cached data and is immune to eviction by execution memory. Default value is 50% of unified space.

Default values work great for most of the workloads. However, you can fine tune memories based on your application needs.

Understanding garbage collection is crucial to understand application performance and tuning it correct can save you from real disasters. Garbage collection is the process of collecting old objects to make place for new ones. To tune garbage collection, we first need to understand the Java Heap space. Java Heap space is divided into young generation and old generation.
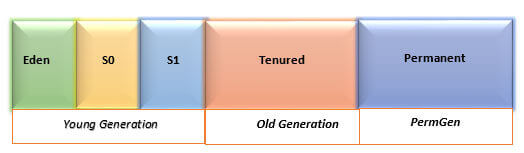
Young generation is further divided into [Eden, Survivor S0, and Survivor S1], which holds short-lived objects. When Eden space gets full, a minor GC is invoked and alive objects move to survivor space. If survivor space gets full, alive objects move to the old generation.
Old generation: holds long-lived objects. If old generation gets full, a full GC is invoked that is a time taking process
We can collect the stats of Garbage collection by adding -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps to the Java options which will print the message in worker’s logs.
- Large object should be stored in serialized form, using the serialized Storage Levels such as MEMORY_ONLY_SER
- If there are too many full GC invoked for a task, it means there is not enough memory for task execution.
- If there are too many minor collections invoked as compared to major GC, then increasing Eden memory could improve performance.
- If old generation is close to full capacity, you can decrease the size of either young generation or you can decrease the spark.memory.storageFraction to reduce the number of cached objects.
- G1GC garbage collector can reduce performance bottlenecks in some scenarios since it involves low pause time and unified storage for short-lived as well as long-lived objects. Thus, switching to a G1GC garbage collector can sometimes improve the performance.
In conclusion, tuning is a time consuming process that needs a hit and trial mechanism since every application has different requirements and may need different kinds of tuning. Sometimes, one trick works for one and another trick works for the next. However following best practices as mentioned in this article will always do the trick.

