

In this blog, let us go through some of the very important tuning techniques in Apache Spark. Apache Spark is a distributed data processing engine and it distributes work on clusters and data processing is performed in parallel. We have to take care of a few things so that work is evenly distributed and jobs run in an efficient manner.
Here are the top 8 tuning techniques which can be used to improve the performance of the Apache Spark application:
- 1. Understand the data and use correct file formats
- 2. Choice of RDDs, Dataframes and Datasets makes impact
- 3. Make sure your data is evenly distributed
- 4. Use correct joining operations
- 5. Persist and unpersist data
- 6. Avoid costly operations if unnecessary
- 7. Memory management matters
- 8. Use UDFs in an efficient manner
Now let us go through each of the above points and understand them better which can help us to improve the performance.
1. Understand the data and use correct file format
You have to understand your data in the first place to get better performance from Apache Spark services. If your dataset has a lot of columns and you are required to perform operation on only a few columns then you can choose to go for Parquet format. Because Parquet is column-oriented data storage format. Parquet provides efficient encoding and compression techniques. We can do predicate pushdown and select only required data thereby pulling just what is required.
If you are trying to select the entire row unlike the above situation, then you can choose Avro file format. Avro is a row oriented RPC and data serialised framework where your data is already serialized and stored in a file. When it is required to transfer data between the nodes, it can be easily achieved and provides better performance as data is already serialized.
We can also use other formats like JSON, CSV but as they have to be serialized first and then transferred across nodes. This causes slight performance degradations. But if your business requirement is to use the CSV or Text files, you can still go ahead and use them.
2. Choice of RDDs and Datasets makes impact
Use RDDs only when it is required to work with unstructured data and once your preprocess is done and data is more organised start using Dataframes and Dataset API to process data. If you are working with the structured data then always go for Dataframes and Dataset API.
Datasets API uses more optimised catalyst optimizer and tungsten improves the memory and CPU utilization. Datasets use encoders and they can be selected and map operated without being deserialized. The main difference between dataframe and dataset is the former untyped and latter is strongly typed API.
3. Make sure your data is evenly distributed
As Spark works in a distributed fashion and data is distributed across the worker nodes, when it starts processing data and if one of the tasks takes time longer than other tasks. It has to wait for the completion of that task to go ahead with the next operation. This usually happens if your data is not properly distributed and you can check this in the Spark web UI.
During this time try to distribute your data using coalesce and repartition operations available in Spark API. Sometimes the data will be skewed and you have to distribute data evenly in all partitions. You can use salting technique available to avoid this situation and get better performance.
4. Use correct joining operations
If you are joining two tables and one of the tables is very small and the other is quite big one, you can use broadcast join. What broadcast join does is, it sends a copy of a small table to each worker node and it is available in local to each executor. Hence it gives better performance when one of the tables is very small.
When you have both tables of equal sizes then SortMerge joins can be used instead to get better performance.
5. Persist and unpersist data
Persisting your data helps because Spark doesn’t have to recompute your data when it requires the transformed and aggregated data multiple times in later stages. Try to understand the right candidate to be persisted, simply persisting many of the datasets will not help.
Try to find the datasets that will be used multiple times in a later stages and which will be time consuming to recompute that dataset, that will be the candidate to be persisted. Once data is persisted, unpersist the data at the end of your execution. Because it clears the persisted data and makes space available for both storage memory and working memory.
6. Avoid costly operations if unnecessary
Omit those operations which you have added during the development and testing phase for validations. Count is one of the expensive operations and it should not be really used unless it is required to use them by business requirement.
If it is okay to get an approximate distinct count use approxDistinctCount() instead of distinct count. Whenever you want to decrease the number of partitions go for coalesce than the repartition operation because coalesce combines data within the nodes first and avoids a lot of data shuffle. It is a good practice to use dropDuplicates() before joining the tables
7. Memory management matters
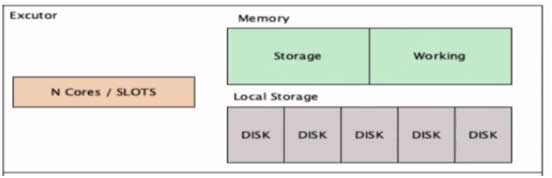
This is how a Spark executor would look like, we have memory and that memory will be shared by both storage layer and working layer as storage memory and working memory. At the beginning all the memory would be available as working memory and once we start caching and persisting data, storage memory keeps increasing and it can use upto 50 percent by default.
So unpersiting the cached and persisted data will have impact on the performance of the Spark application.
8. Use UDFs in an efficient manner
You know using UDFs in a spark application is tricky and you can use the available functions in spark-sql functions to achieve your results. You have to remember that scala UDFs are faster than Python UDFs, but if you vectorize the python UDFs you will gain much better performance sometimes close to Scala UDFs and sometimes better than scala UDFs.

