

GCP, BigQuery and Issues

Introduction and Problem
Google BigQuery is in trend these days. So why this hype and what makes it better than its competition. What is GCP? What is the relation between BigQuery and GCP? What are Issues related to both?
If you are the one who wants to get answers to the above questions then read below. In this blog we will quickly talk high-level understanding on what is Google BigQuery and GCP and also will discuss one of the Use Case/Issue related to it.
What is GCP?
GCP stands for Google Cloud Platform which is an amalgam of products and services which allow building applications on Google's software and infrastructure.
Under this umbrella comes many products, most notable are Google App Engine, Google Compute Engine, Google Cloud Storage, BigQuery, Google Cloud SQL, Google Container Engine, Dataflow, Cloud Endpoints, Prediction API etc. Ever wondered how a real time GCP Web URL looks like? Below is a screenshot of a real time GCP Web URL:
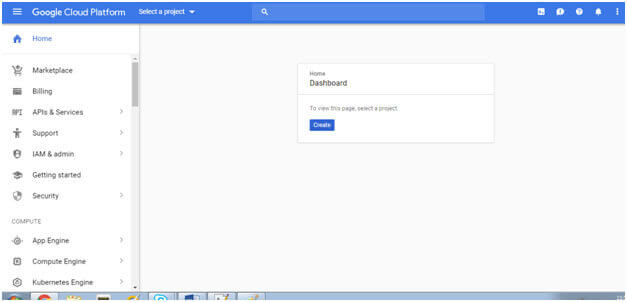
We can create our own project or modify an already existing project through this dashboard. As you can see there are many other options in the left corner wherein we can go ahead and make modifications to our already existing GCP Project.
Everyone who has to work on BigQuery has to first create a project in this dashboard and then only can work on BigQuery. This is a free to use web URL for a specific period of time, you can always go to the below link to quickly sign up for a free trial, just login through your Gmail id and start creating your GCP projects and do some hands on to get a fair idea on how GCP works.
What is BigQuery?
Now Google BigQuery is a powerful serverless solution for data warehousing to store petabytes of information and retrieve it in seconds using standard SQL. Its uniqueness is in its super-fast data retrieval and as it’s completely managed we don’t have to take care of anything, everything is managed by bigquery itself. It uses the processing power of Google’s infrastructure.
Best part is we can even control access to both project and data e.g. providing others ability to view or query your data. We need to first have a project, databases and tables to query data. This dataset can be created or can be imported from other relational databases or even Hadoop. BigQuery is much faster than map reduction or spark in Hadoop.
Setting GCP in Linux Env:
We have to install Google Connector software in all the Linux machines of a particular cluster. To do this we have to copy certain jars and JSON files to each machine. Moreover we have to create “keys” and “gcs-connector” directories in all of the servers. Once this is done we can check if Google connector is installed successfully or not. We can check this through below command:-
Approach us to get a solution as we are specialised in handling GCP and Big Data.
Hadoop dfs –ls gs://
It is recommended to create a test directory before and then check this.
Moreover we may need to do Google export command in case of any issues:- gsutil ls
Export HADOOP_CLASSPATH=/opt/cloudera/parcels/CDH-5.7.1-
1.cdh5.7.1.p0.11/lib/hadoop-hdfs/lib/*
NOTE:- Above path need to be changed according to your directory setup.
After this setup we will be able to use Google BigQuery and will be able to load and fetch data.
MySQL vs Google BigQuery performance comparison:
As per my analysis compared to MySQL, BigQuery retrieved data 3 times faster with no other downsides.
BigQuery Use Case:
In one particular BigQuery use case, relying on the right data warehouse consulting helps import data to BigQuery from Hadoop using a Python script and then query this data. Data retrieval was super-fast compared to Hadoop. We were using spark in Hadoop before migrating to BigQuery. We had to install Google Connector software for this project before starting to query the data.
Moreover we can also directly query data from Hadoop but we saw that this took longer time to query data and was not feasible hence we imported data to BigQuery then Query the data.
BigQuery Downsides:
In case if we query your data a lot then BigQuery can end up being very expensive as it also charges per data processed on a query. We have to pay for each query we make hence in the long run it can be a costly deal compared to other solutions.
Hope you enjoy reading this article, it is uploaded by our senior team member of Big Data Developers, Aegis Softtech provides big data consulting services to resolve your big data, GCP and BigQuery related issues and get the best out of your data.
We will talk about other GCP and Google BigQuery Issues in another BLOG, Happy Reading!

