Oozie is a well-known workflow scheduler engine in the Big Data world and is already used industry wide to schedule Big Data jobs. Oozie provides a simple and scalable way to define workflows for Big Data pipelines. These pipelines are essential for modern data warehousing, as they automate the extraction, transformation, and loading (ETL) processes required to keep analytical databases up-to-date.
Internally Oozie workflows run as Java Web Applications on Servlet Containers. In this blog, we will look into what oozie support, how it works and how we can write workflows using oozie.
What Oozie Supports?
Oozie is well integrated with various Big data Frameworks to schedule different types of jobs such as Map-Reduce, Hive, Pig, Sqoop, Hadoop File System, Java Programs, Spark, Shell scripts and Many more.
How Oozie Work?
Oozie is internally written in Java but we can write our workflows using XML or Java. In xml, we have to define various action nodes and control nodes to define the flow of our system.
For example, Suppose you want to build a big data pipeline in which the first step is to import some data from oracle database using Sqoop Job and the next step we want to create schema/table for that using Hive and final step is to run some transformation/analytics using apache Spark MapReduce job before saving it the database. This overall pipeline can be specified using oozie workflows.
Tired of writing workflows for big data jobs?
Our expert team does the task within no time using the Oozie workflow scheduler engine and simplifies the task.
What are the Terminologies in Oozie?
Workflow
Workflow is a definition file written in XML that defines the DAG (Directed Acyclic Graph) to run the overall flow using action and control nodes.
Action Nodes
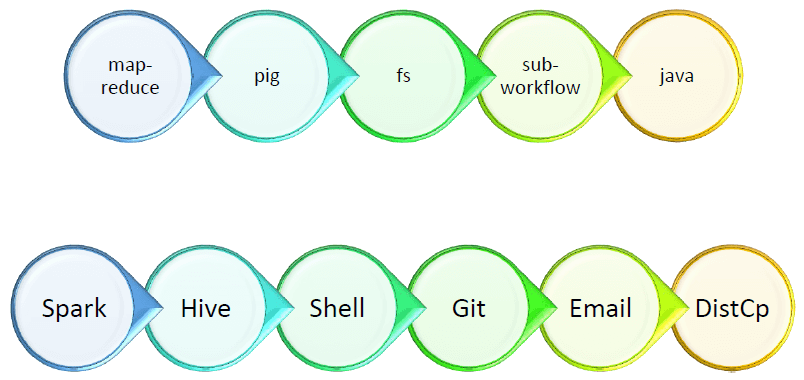
Action nodes trigger the execution of some task written in MapReduce, Pig, Hive or Sqoop etc. You can also extend oozie to write customized action nodes. Below are the examples of action nodes supported by oozie workflow.
Control Nodes
Control Nodes control the flow path and also specify the starting and ending of workflow. Below are the examples of control nodes supported by oozie workflow
Control Nodes
Starting & Ending a Workflow
These control nodes specify the start and end of your workflow and you can provide any arbitrary name to these nodes.
<workflow-app name="sample-workflow" xmlns="uri:oozie:workflow:1.0">
<start to="firstJob" />
...
<end name="end" />
</workflow-app>
Killing a Workflow
This control node can kill a workflow and can return the output reason as whatever is provided in the message field. You can provide a name and a reason in the message field for getting killed.
<workflow-app name="sample-workflow" xmlns="uri:oozie:workflow:1.0">
...
<kill name="killthisflow">
<message>Response not received</message>
</kill>
...
</workflow-app>
Making a Decision
Decision nodes can be used to decide the flow in a workflow by providing a condition in switch case statements. You can define any predicate inside your case statement to control the flow.
<workflow-app name="sample-workflow" xmlns="uri:oozie:workflow:1.0">
<decision name="decision">
<switch>
<case to="FetchCustomerData">${type eq "sqoop"}</case>
<case to="DefineSchema">${jobType eq "hive"}</case>
<default to=" FetchCustomerData " />
</switch>
</decision>
<action name=”FetchCustomerData”>
<sqoop xmlns="uri:oozie:sqoop-action:0.2">
...
</action>
</workflow-app>
Splitting & Joining
You can split your execution path into concurrent execution paths using Fork control nodes and you can also wait for the concurrent execution path to complete using Join Control Node.
In the below example, Fork control node will split the workflow into two concurrent MapReduce jobs named as “firstjob” and “secondjob”. When both jobs get completed only then third MapReduce job named as “thirdjob” will get executed.
<workflow-app name="sample-wf" xmlns="uri:oozie:workflow:1.0">
...
<fork name="Split">
<path start="firstJob" />
<path start="secondjob" />
</fork>
<action name=" firstJob ">
<map-reduce>
...
</map-reduce>
<ok to="joinResult" />
<error to="killWorkflow" />
</action>
<action name="secondjob">
<map-reduce>
…
</map-reduce>
<ok to="joinResult" />
<error to="killWorkflow" />
</action>
<join name="joinResult" to="thirdjob" />
<action name="thirdjob">
<map-reduce>
…
</map-reduce>
</action>
...
</workflow-app>
Action Nodes
Though Oozie supports various types of jobs. In this blog, we will discuss only MapReduce, Spark, Sqoop & HDFS Action workflow samples.
MapReduce Action
If you want to execute MapReduce jobs using oozie engine, we need to define job tracker, name-node details, Mapper class, Reducer class, input and output directory. We can also configure more configuration parameters, but these are the base parameters.8n8
<workflow-app name='sample-wf' xmlns="uri:oozie:workflow:0.1">
<action name='countCustomers'>
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.mapper.class</name>
<value>com.sample.CustomerCount.Map</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>com.sample.CustomerCount.Reduce</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>${inputDir}</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>${outputDir}</value>
</property>
</configuration>
</map-reduce>
<ok to='end' />
<error to='end' />
</action>
</workflow-app>
Sqoop Job
Oozie also provides support to run Sqoop commands directly in workflow using Sqoop action nodes. You can also specify a Sqoop job but in the example below, we are going to fetch all records from the customers table in MYSQL and store the result in HDFS location.
<workflow-app name="sample-wf" xmlns="uri:oozie:workflow:0.1">
...
<action name="fetchCustomers">
<sqoop xmlns="uri:oozie:sqoop-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${jobOutput}" />
</prepare>
<command>import --connect jdbc:mysql:file:db.hsqldb --table customer --target-dir hdfs://localhost:8020/user/customers -m 1</command>
</sqoop>
<ok to="hivejob" />
<error to="error" />
</action>
...
</workflow-app>
Hive Job
<workflow-app name="sample-wf" xmlns="uri:oozie:workflow:0.1">
...
<action name="myfirsthivejob">
<hive xmlns="uri:oozie:hive-action:0.2">
<job-traker>
foo:9001</job-tracker>
<name-node>bar:9000</name-node>
<prepare>
<delete path="${jobOutput}" />
</prepare>
<configuration>
<property>
<name>mapred.compress.map.output</name>
<value>true</value>
</property>
<property>
<name>oozie.hive.defaults</name>
<value>/usr/foo/hive-0.6-default.xml</value>
</property>
</configuration>
<script>
myscript.q
</script>
<param>InputDir=/home/tucu/input-data</param>
<param>OutputDir=${jobOutput}</param>
</hive>
<ok to="myotherjob" />
<error to="errorcleanup" />
</action>
...
</workflow-app>
HDFS Action
Oozie Workflow also provides us to work with HDFS storage and to run HDFS commands.
<workflow-app name="sample-wf" xmlns="uri:oozie:workflow:1.0">
...
<action name="hdfscommands">
<fs>
<delete path='hdfs://foo:8020/usr/tucu/temp-data' />
<mkdir path='archives/${wf:id()}' />
<move source='${jobInput}' target='archives/${wf:id()}/processed-input' />
<chmod path='${jobOutput}' permissions='-rwxrw-rw-' dir-files='true'>
<recursive />
</chmod>
<chgrp path='${jobOutput}' group='testgroup' dir-files='true'>
<recursive />
</chgrp>
<setrep path='archives/${wf:id()/filename(s)}' replication-factor='2' />
</fs>
<ok to="myotherjob" />
<error to="errorcleanup" />
</action>
...
</workflow-app>
Spark Action
Oozie also provides extended support to run Spark actions.You can define various configurations to run spark job such number of executor, output compressions, memory required and much more to run your spark application.
<workflow-app name="sample-wf" xmlns="uri:oozie:workflow:1.0">
...
<action name="myfirstsparkjob">
<spark xmlns="uri:oozie:spark-action:1.0">
<resource-manager>foo:8032</resource-manager>
<name-node>bar:8020</name-node>
<prepare>
<delete path="${jobOutput}" />
</prepare>
<configuration>
<property>
<name>mapred.compress.map.output</name>
<value>true</value>
</property>
</configuration>
<master>local[*]</master>
<mode>client</mode>
<name>Spark Example</name>
<class>org.apache.spark.examples.mllib.JavaALS</class>
<jar>/lib/spark-examples_2.10-1.1.0.jar</jar>
<spark-opts>--executor-memory 20G --num-executors 50 --conf spark.executor.extraJavaOptions="-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp"</spark-opts>
<arg>inputpath=hdfs://localhost/input/file.txt</arg>
<arg>value=2</arg>
</spark>
<ok to="myotherjob" />
<error to="errorcleanup" />
</action>
...
</workflow-app>
Oozie Command
Running Oozie Workflow
oozie job -oozie http://localhost:11000/oozie -config job.properties -run
Killing Oozie Workflow
oozie job -oozie http://localhost:11000/oozie -kill 14-20090525161321-oozie-joe
Suspending Oozie Workflow
oozie job -oozie http://localhost:11000/oozie -suspend 14-20090525161321-oozie-joe
Resuming Oozie Workflow
oozie job -oozie http://localhost:11000/oozie -resume 14-20090525161321-oozie-joe
Apache Airflow versus Oozie
Apache Airflow is a new scheduling engine introduced in Big Data World to schedule big data jobs. Its immense popularity contributes to the fact that it can be used to build complex data pipelines. However, in order to write workflows in Apache Airflow, you must know about python development services.
Oozie is a well-known and adopted scheduling engine since a decade but recently a new scheduling engine called Apache Airflow is marking its place in the market. What is the difference between the both?
Oozie is written in Java internally and workflows can be written in XML language. So a non-programmer can also write workflows using oozie where as in order to write workflows in Apache Airflow, you need to learn python language.
Oozie can be used to write simple pipelines but in order to write complex pipelines you can look further for Apache Airflow where you can write complex logic and can integrate with Cloud, Kubernetes and many other technologies.
Conclusion
Oozie remains a top choice for scheduling big data pipelines due to its simplicity and stability. Through our data warehouse consulting engagements, we’ve found that for many standard enterprise use cases, Oozie provides the perfect balance of reliability and ease of use compared to newer, more complex tools.