Introduction to MapReduce
This blog consists of fundamentals of MapReduce and its significance in Hadoop development services. MapReduce is a programming model that performs parallel and distributed processing of large data sets. Leveraging the power of Python Development Services, this model simplifies the development and execution of complex data processing tasks.
Following are the topics that will be covered in this tutorial blog:
- Map Reduce distributed processing: Traditional way
- What is Map Reduce with Example?
- Commands used in Map Reduce
- Map Reduce Program Example

1. Map Reduce distributed processing: Traditional way
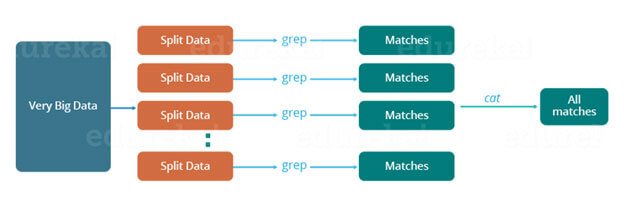
We can take football statistics as an example. For example, if I want to know the top scorer. First, I'm going to try to get all the data. Then I'm going to turn it into small blocks or sections. I'm going to collect it in different machines and try to get my response. So essentially, I'm going to get my results, but during the process we can see several challenges.
- Critical path issue: the amount of time required to complete the job without missing the next milestone or actual completion date. Therefore, if any of the machines postpone the job, it will delay the entire work.
- Reliability issue: What if any of the machines that operate with some information fails? It becomes a challenge to handle this bulk failure.
- Equal split issue: How do I split the data into smaller chunks so that even part of the data can be used for each device. In other words, how to split the data equally so that no one device is overloaded or under-used.
- Single split can fail: if any device fails to provide performance, I will not be able to determine the outcome. There should therefore be a mechanism to ensure the system's ability to tolerate this fault.
- Result aggregation: The result generated by each machine should be aggregated to produce the final output.
These are the issues that I will have to take care of individually while using traditional approaches to perform parallel processing of huge data sets. For handling these challenges efficiently, our Python development company can provide the necessary expertise and solutions to ensure effective data processing and result aggregation.
We have the MapReduce framework to overcome these data analytics solutions, which allows us to perform such parallel computations without bothering about issues including reliability, fault tolerance, etc. MapReduce therefore gives you the flexibility to write code logic without worrying about the system's design problems.
2. What is MapReduce?
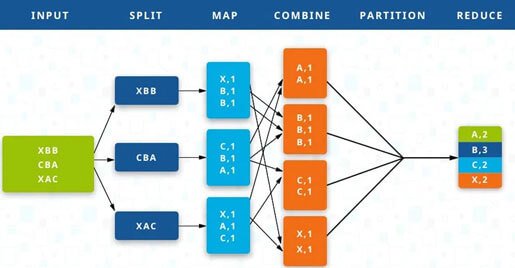
MapReduce consists of two different tasks – Map and Reduce. As suggested by the name MapReduce, the reducer phase takes place after completion of the mapper phase. So, the first is the map job, where a data block is read and processed as intermediate outputs to produce key-value pairs.
Are you finding solutions to handle large data sets without such issues? Are you struggling to overcome Data analytics solutions? Contact us to get the awareness of MapReduce and process intermediate outputs with ease.
Input to the Reducer is the output of a Mapper or map job (key value pairs). The reducer receives from multiple map jobs the key-value pair. The reducer then aggregates these intermediate tuples of data (intermediate key-value pair) into a smaller set of tuples or key-value pairs that is the final output.
3. Commands used in Map Reduce
| Commands | Tasks |
|---|---|
| hadoop job -submit <job-file> | This command is used to submit the Jobs created |
| hadoop job -status <job-id> | This command shows the map and reduce completion status and all job counters |
| hadoop job -kill <job-id> | This command kills the job |
| hadoop job -events <job-id> <fromevent-#> <#-of-events> | This shows the event details received by the job tracker for the given range |
| hadoop job -history [all] <jobOutputDir> | This is used to print the job details, killed and failed tip details |
| hadoop job -list[all] | This command is used to display all the jobs |
| hadoop job -kill-task <task-id> | This command is used to kill the tasks |
| hadoop job -fail-task <task-id> | This command is used to fail the task |
| hadoop job -set-priority <job-id> <priority> | Changes and sets the priority of the job |
| HADOOP_HOME/bin/hadoop job -kill <JOB-ID> | This command kills the job created |
| HADOOP_HOME/bin/hadoop job -history <DIR-NAME> | This is used to show the history of the jobs |
| Parameters | Tasks |
|---|---|
| -input directory/file-name | Shows Inputs the location for mapper |
| -output directory-name | Shows output location for the mapper |
| -mapper executable or script or JavaClassName | Used for Mapper executable |
| -reducer executable or script or JavaClassName | Used for reducer executable |
| -file file-name | Makes the mapper, reducer, combiner executable available locally on the computing nodes |
| -numReduceTasks | This is used to specify number of reducers |
| -mapdebug | Script to call when the map task fails |
| -reducedebug | Script to call when the reduce task fails |
4. Map Reduce Program Example
Mapper.py
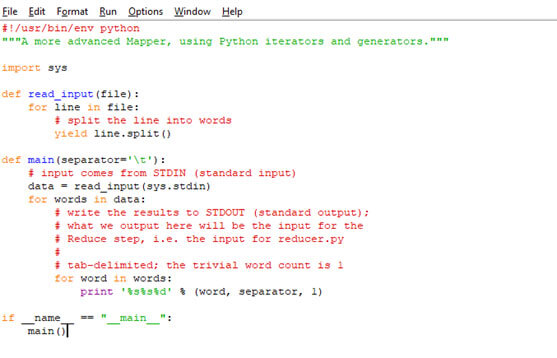
Reducer.py