

Apache Pig is used for summarization and query analysis of data and how this data will load into the Hive Partition column. This tutorial will be explained by a big data analytic services provider. Here big data service provider introduces a very simple way to understand hive partition and use of pig in hive partition column and further information.

What exactly is Big Data?
As per one of the analysis we create approximately 2.5 quintillion bytes of data everyday – the pace at which data is growing can be summed up by saying that 80% - 85% of the whole data has been created in the last 2 years. It has volume, velocity and variety and IBM adds the latest V – Veracity to it, this much data is processed for useful insight and decision making.
Today, we gather data from everywhere, whether it can be sensor data, cell phone data, stock exchange data, social media data and transactional data to name a few. Above all stuff can be named as Big Data. And to process this much amount of data we have a Hadoop framework in place where we can ingest the data, process the data and schedule it.
Processing of data which includes transformation/cleaning/profiling of the raw data leads to the refined data which can be useful for further BI analytics services to extract meaningful information for the organizations, for processing of data there are 2 main tools in Hadoop framework – Hive and Pig.
Technology
Pig is mainly used to clean and filter raw or unstructured data, while Hive is used to query data stored in a DWH or Data Lake. Most data warehousing solutions utilize this specific combination to transform raw HDFS logs into structured, queryable tables.
Partitioning in Hive and loading data into the Hive table after cleaning or profiling data from Pig are very common trends but we still have few limitations when we try to merge both the methods.
Use-case:
Below is the sample data screen shot which we will use to load into the Hive table.
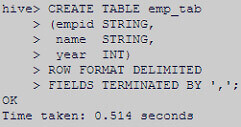
Create Hive table named emp_tab
Load the data into the Hive table which we have created above.

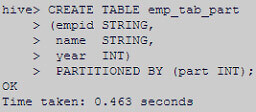
Created another Hive table but with partitioning column name – ‘part’.
Setting Dynamic partitioning conditions to TRUE
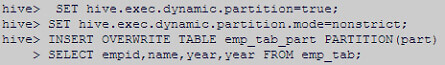
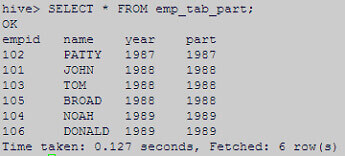
Below is the output of the partitioning table, one can see data partition column also.
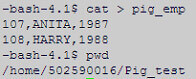
We have taken sample data to load it into Pig, which would be further used to move into the Hive table.
Enter into Pig with HCatalog option.

Load the data into Pig relation ‘A’ from the HDFS path.

Appending the above stored data from Pig to the Hive table – emp_tab (non-partitioned).

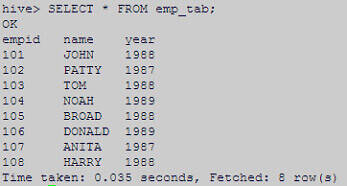
Below screenshot shows that data has been successfully added in Hive table with 107 and 108 as id’s.
Issue:
After successfully loading data from Pig relation to the Hive table (non-partition), we thought it would behave the same for the non-partition table.
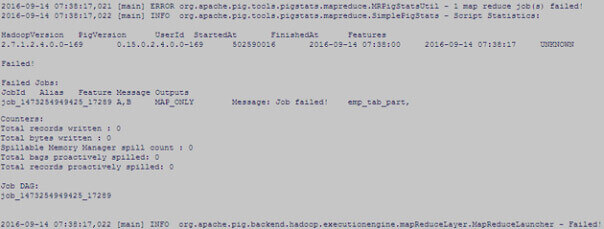
So we tried to load the data into the partition table – emp_tab_part from Pig.
Our techies will help you out with loading of summarized and analysed data into hive partition using pig.
To achieve the above requirement we have to add another column in Pig relation.
We will create another relation – ‘B’ and add the column name – ‘part’ into it and store the data into the ‘emp_tab_part’ table traditionally.

But it failed with below error.
Resolution:
Through our extensive data warehouse consulting experience, we’ve found that loading data into a Hive partition column from a Pig relation requires static handling to ensure data integrity and partition accuracy.
Below are the partitions sub-directories under the table directory ‘emp_tab_part’.

We have separated out the pig data according to the partition column placed in the Hive table.
In our example, the partition column is based on year so we will put record with year 1987 in one relation (B_1987) and record with year 1988 under another relation (B_1988). Then generated the 4th column with the name ‘part’ with the year column.

Now use the STORE command to load the data into 1st partition (part=1987) from B_part1 but make sure to add the name of the partition directory (in HDFS) in which you want to load the data.

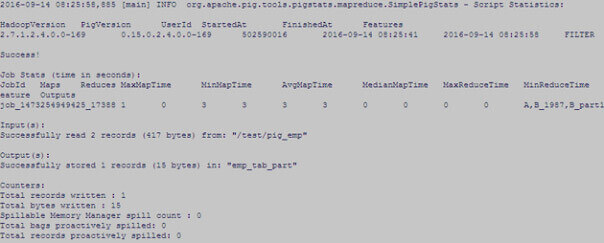
Follow the same steps for the other partition – 1988.

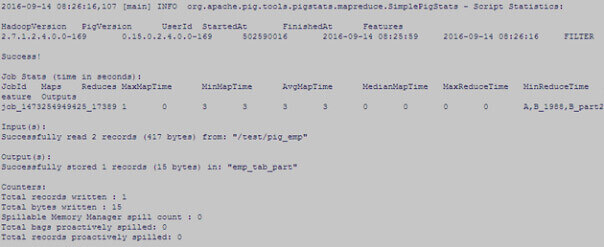
Data has been successfully loaded into the partition Hive table.
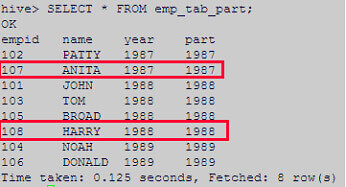
Conclusion:
From the above research it is clear that we cannot load the data into the Hive partition column dynamically and we have to go statically then also we cannot go traditionally and have to follow certain steps for the same.
Big data consulting services provider from India has just shared this tutorial post with global big data and hadoop community developers who want to know more about Apache Pig.
They have explained a tutorial about the use of Pig for loading data into the Hive partition column. If there is anything unclear, ask in comments.

