

Most data warehouses are built using dimensional modelling technique as it involves complex hierarchy of relationship. In order to satisfy the need of large data warehouses , database tables are divided into certain categories based upon level of data abstraction.
Following are the categories:
- Dimensions
- Facts
Dimensions
These kinds of catalog tables include descriptive information having related attributes which will be accessed by distinct key values.
It acts as a page of the book rather than index as it contains detailed data related to context. Dimension tables are of definite scope, i.e Accounts dimension will have Saving or Current account. As it has limited scope it can be used to get reference from.

Facts
Unlike dimension tables, fact tables don't have descriptive information instead it holds reference from dimension table. These tables act as indexes of a book rather than pages.
Fact table may have data from more than one dimension table to satisfy complex relationships. Usually these tables contain large amounts of data due to aggregation from multiple sources.
So here our objective is to populate the fact table from two sources Apache Hive and CSV source file. This can be achieved by using various built in components provided by Pentaho Data Integration (PDI).
We take care of all tasks related to retrieving data from the data lake.
For small amounts of data we can use these components directly without any alteration in implementation. But, while dealing with a huge data-set, we need to modify the flow of simple Pentaho ETL using different utilities that are available in PDI.
To populate fact table from different source we are following below data flow diagram:
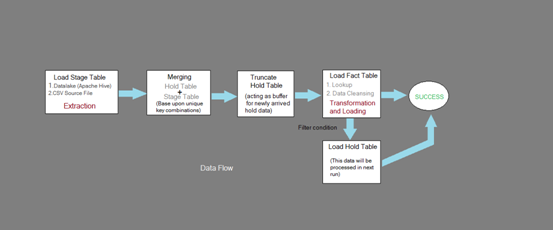
EXTRACTION
First data is extracted from Apache Toad(Hive) OR CSV Source File.
MERGING
Hold data which is present from last run in hold table is merged with stage table to reprocess it.Merging is done based upon unique key combinations
TRUNCATE HOLD TABLE
After merging data from the previous run into the stage table, we are good to truncate the hold table as its data is present in the stage table. So, Hold table will be ready for the next run.
TRANSFORMATION AND LOADING
Once data is populated into the stage table, We are going to perform various lookups and data cleansing activities.
During this step data is transformed and loaded into both fact and hold tables.
LOAD HOLD TABLE
Records satisfying the filter condition will be moved to the fact table, whereas other data is placed into the Hold table for processing during the next run.
We are implementing an incremental load job as it is widely used in data warehouses. Below is job which will bulkload into fact table
FactLoad_Job.kjb:
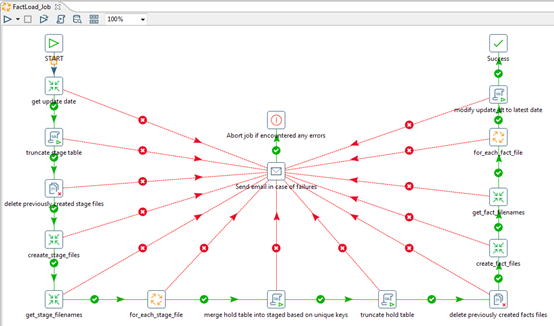
During execution of any step from the above job, if any error encountered it will immediately send email notification by using the Mail component of Pentaho Kettle. After sending email, Job will be aborted.
-
get_update_date.ktr:
This transformation will get the last update date till which records are already processed as it is incremental load. So we will be able to get records which are unprocessed.
It will save the date into variable update_date.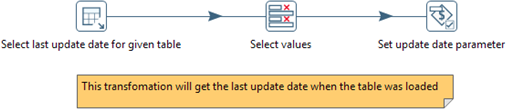
-
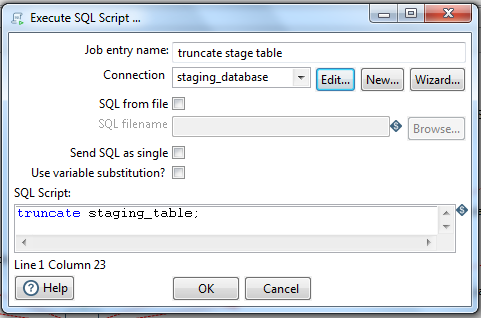
truncate stage table:
This step truncates the stage table 'staging_table' to load the new data after the update_date.
-
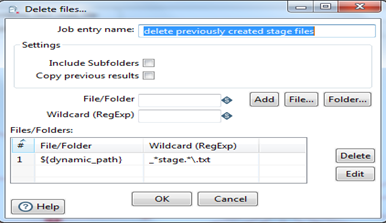
delete previously created stage files:
This step finds and deletes the previously created fact load files in the out folder path '${dynamic_path}' with a RegExp '*_stage .*\.txt'.
-
EXTRACTION:
First data is extracted from Apache Toad(Hive) OR CSV Source File.
-
MERGING:
Hold data which is present from the last run in the hold table is merged with the stage table to reprocess it. Merging is done based upon unique key combinations.
TRUNCATE
-
-
create_combine_stg_load_file.ktr:
This step pulls the data from Apache Hive ‘Hive_table’ source table.It creates the stage load files with '|' separator in a chunk of 200000 records. File will be created at the '${dynamic_path}/hive_stage' location. If parent folder is not present then it will automatically create the folder
-
Replace variables in script?
Check this checkbox when you want to replace the parameter value from a variable which you have set already.
-
-
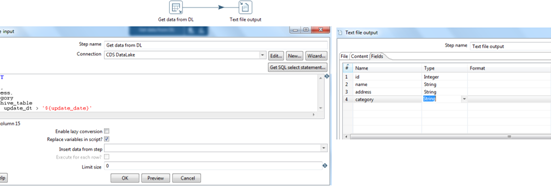
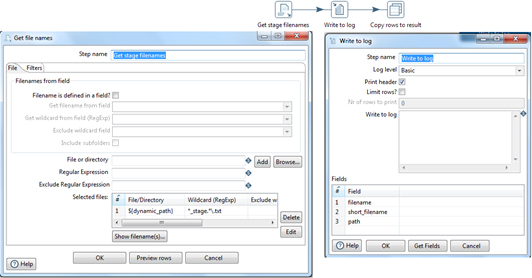
get_stage_filenames:
This step executes 'get_stage_filenames.ktr' transformation. This is a common transformation to get all stage file names.This step finds previously created stage load files from the folder path '${dynamic_path}' with a RegExp '${file_name}_stage.*\.txt'. Parameters 'directory_path' and 'file_name' are declared in the main Job.
-
for_each_stg_file.kjb:
This step executes 'set_var_filename.ktr' transformation. This is a common transformation to set filename. Set Variables sets the variable 'filename', its scope will be valid in the parent job. bulkload_into_stage_table.kjb performs the bulkLoad into 'staging_table' by reading each stage file which was created previously , one by one.
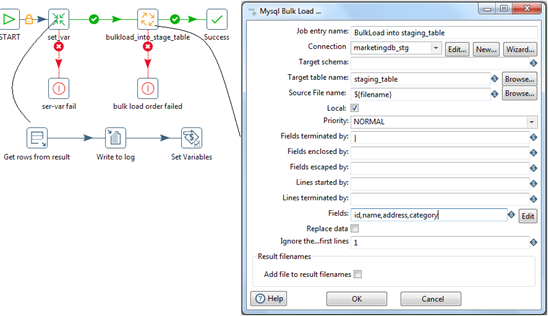
-
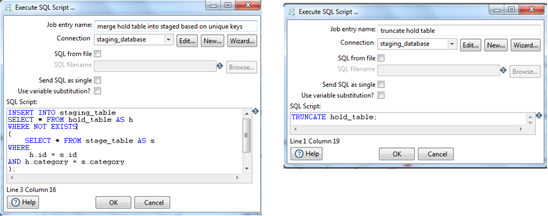
merge hold table into staged based on unique keys:
In this step, merge the hold table 'hold_table' into staged table 'staging_table'.
-
truncate hold table:
This step will truncate the "hold_table" table so that for the next run it will be empty.
-
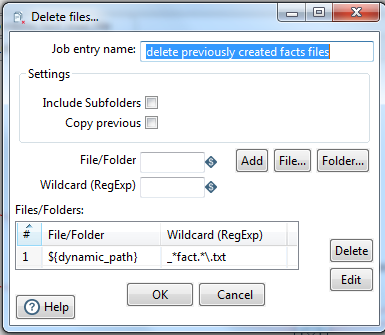
delete previously created facts files:
This step finds and deletes the previously created fact load files in the out folder path '${dynamic_path}' with a RegExp '*_fact.*\.txt'.
-
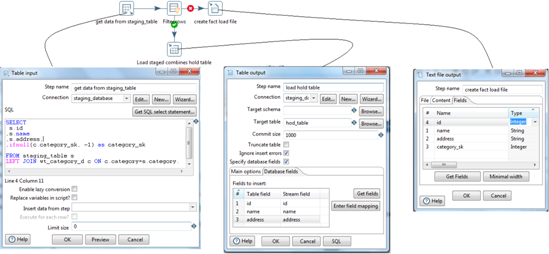
create_fact_files.ktr
This step gets the data from staging table 'staging_table' and joins it with the wt_category_d to get data and surrogate keys.
Filter rows filters the rows coming from the previous step. If category_sk is -1 then records go into step 'Load hold table' otherwise go into step
'create_fact_load_files'.
create_fact_load_files will creates the fact load files with '|' separator in a chunks of 200000 records.File will be created at '${dynamic_path}/*_fact' location.
If the parent folder is not present then it will automatically create the folder.
-
get_fact_filenames.ktr:
This step finds previously created fact load files from the folder path '${dynamic_path}' with a RegExp ' *_fact.*\.txt'.
Parameters 'directory_path' and 'file_name' are declared in the main Job.
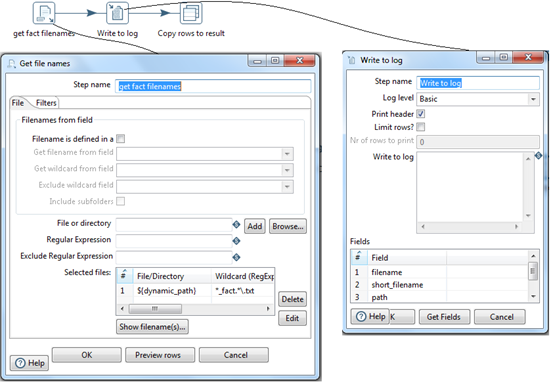
-
for_each_fact_file.kjb:
“set_var.ktr” step gets the rows from the previous result.
”Set Variables” step sets the variable 'filename', its scope will be valid in the parent job.
“bulkload_combine_fact.kjb”This step performs the bulkLoad into 'wt_digital_refunds_f'-
Replace Data: Check this checkbox to replace the data based on Unique Key combinations.
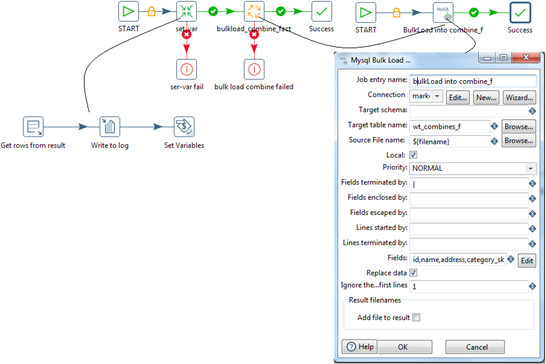
-
-
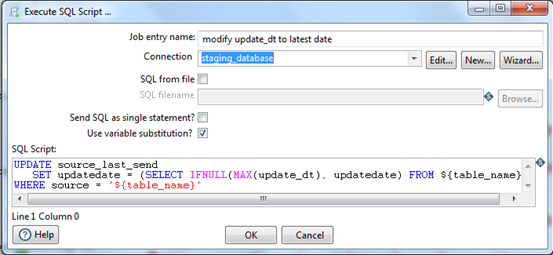
modify update_dt to latest date:
This step will update update_dt into the repository table from which date will be fetched during the next incremental run. Here, source_last_send is a repository table which keeps track of the latest date. And table_name is the name of the stage table.
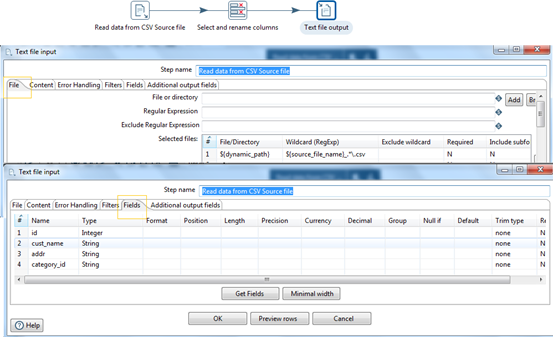
In order to load data from CSV source files, the only transformation needed to change is create_stage_files.ktr. Specify the file type in the content tab as CSV.
Conclusion :
Database lookups and table output component works fine with few thousands records table.But it is having poor performance with huge datasets.
With the help of Pentaho data integration utility components and slight changes into data flow can get improved performance and maintainability while working with large data-set.
If it is necessary to process a huge scale of data for you, then Apache Spark is a quick and common framework built for emphasizing over large portions of data. As Spark is quickly experiencing enterprise adoption, Aegis Softtech delivers Apache Spark Services to make the framework easy and flexible for all your data processing needs.

