

With the growing size of data everyday, the need for business Intelligence is also thriving like never before. Business Intelligence is about analyzing data to gather some business insights to take better business action and this analysis can be performed with the help of some ETL tools.
Apache Hive is an ETL tool that can query large datasets stored on a Hadoop Distributed File System. The Hive framework was originally designed by Facebook for their business analysts who had limited programming language knowledge but were proficient in running SQL queries to extract business insights. For those interested in leveraging Apache Hive and similar tools in their data analytics workflows, our Java development company can provide valuable insights and support to optimize these processes effectively.
Characteristics of Apache Hive
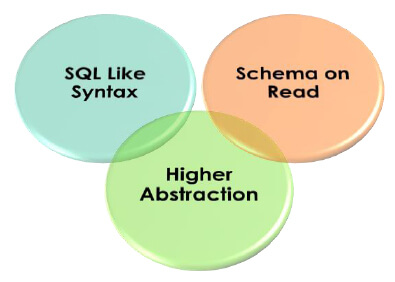
Schema on Read:
Hive is not a database because it does not keep data and schema together. Data is always stored on a Hadoop distributed file system, Hive just imposes schema on top of that data too while reading and that is why it is called schema on Read.
SQL like Syntax:
Hive uses SQL-Like language called Hive Query Language (HQL) to perform analytics on top of data. Apache Hive is extremely famous among Business Analysts & testers who are well acquainted with SQL queries.
Higher Abstraction:
Apache Hive is built on top of Hadoop Framework development and it runs MapReduce jobs in the background. HQL queries are converted into Java programs, which run as Mappers & Reducers on top of Hadoop to perform analysis.
Hive Architecture
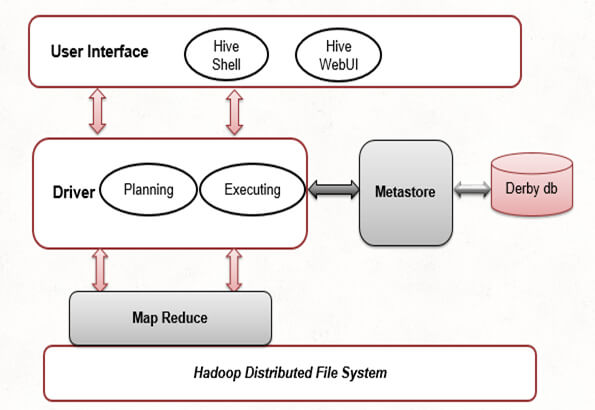
User Interface:
Hive provides an interface between User and HDFS to run HQL queries against data stored in Hadoop File System.Various supported interfaces by Hive are Hive Command Line, Hive Web UI and Hive HDInsight.
Meta Store:
Hive stores the schema and table metadata such as column name, column type, HDFS location (where data is actually stored) on a separate database. By default, a Derby database is used internally to store the schema but it can be replaced by any other database such as postgres, mysql for production environments.
HiveQL Process Engine:
This process engine communicates with the metastore to compile and parse HQL queries.
Execution Engine:
It processes the HQL queries to create a corresponding MapReduce job to run on top of the Hadoop distributed file system to access data and to produce the final output.
Create Database in Hive
To start working with Hive, we need a database in which we can create tables.Below commands can be used to create, describe and drop a database in Hive.
Hive Database
External/Managed Tables
There are two types of tables in Hive – External & Managed tables. Major difference between the two is that if you drop a Managed table, both data & schema attached to the table will be deleted whereas if you drop an external table then only schema associated with the table will be deleted although the data will remain intact on HDFS.
Create Managed Table
Create External Table
Hive Analysis
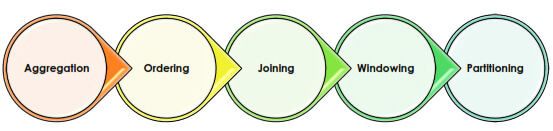
Hive supports various ways to perform data analysis such as
Aggregation:
You can aggregate data using various aggregation API provided by Hive such as count, sum, avg etc.
Ordering:
You can order the data based on one or more columns. Ordering/Sorting in distribution is little different from traditional systems. Either you can sort the data across all machines that will result in data shuffling or you can sort the data within a single machine. Sorting the data within a single machine will not guarantee order across all machines.
Joining:
You can also join the data based on some keys to perform aggregation on top of that joined data.
Windowing:
With the concept of windowing in Hive, you can perform analysis on data falling in some window. For example, you want to find the top searched websites in the last 10 minutes or the highest sold product in the last 7 days.
Partitioning:
You can also partition your data in HDFS. Concept of partitioning data can make queries run faster. For example, in population based data, you can partition data based on country and then on city. Suppose I want to perform some aggregation on population data based on country/city, I can directly jump to partition based on country/city instead of searching entire data that will ultimately decrease query latency.
In this Blog, we will look into Aggregation, Partitioning and Joining.
Aggregation
Suppose I want to find out all the cities in which the number of employees is greater than 100. I can run below HQL query.
City with more than 100 Employees
There are numerous built-in aggregation operations provided by hive such as sum, Min, Max, Avg. In addition, Hive provides String, Date and Math operations to perform advanced Analytics to perform some formatting or advanced analytics.
Partitioning
As already discussed, partitioning makes HQL run faster. In below example, we partitioned the employees data based on employee city. Running the query below will create physical directories on HDFS based on the number of cities and all data belonging to the same city will go to the same partition. For example, Partition with Newyork City will have all employees from Newyork city.
Partitioned based on city
Joining
You can also join data using Hive. For example, we have department and employee data on HDFS and we want to join this data to fetch our employee with department information in the final result. There are various types of joins supported by Hive – Inner Join, Left Outer Join and Right Outer Join. You can join multiple tables together using Join queries in Hive.
Let’s take an example, Suppose we have employee and department information at two separate locations and I want to join this data to get the employee name & his department name in the final result. Below figures represent the dataset and final outcome after applying inner join.
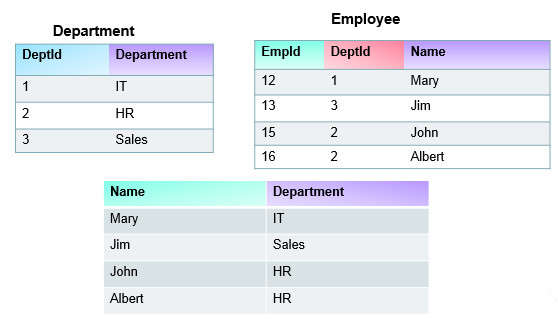
Inner Join based on EmpId
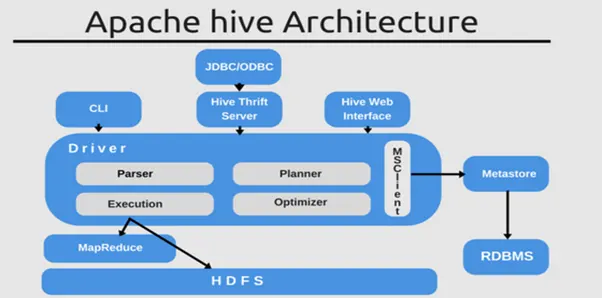
Image source: https://www.analyticsvidhya.com/blog/2022/06/everything-about-apache-hive-and-its-advantages/
Use Cases and Industry Applications
1. Analyzing customer behavior in the e-commerce business
The quite valued user cases for Apache Hive towards eCommerce business is inspecting customer behavior. In the present digital landscape, knowing customer behavior is vital for companies to create informed decisions and enhance their complete performance.
Apache Hive comes with commanding data inquiring and dealing out competencies, lets eCommerce businesses investigate profound client data, and excerpt expressive understandings. By analyzing customer wants, firms could get known material regarding clients' favorites, buying patterns, and connections to have a website platform.
2. Finance Industry
Using Apache Spark, financial organizations that operate retail investment and selling activities can lower the number of clients which leaves the corporate by twenty-five percent. The marketing, finance, exchange, and investing platforms have been separated by the financial organization into their respective categories. Instead, the banks wish to find a picture of the client, irrespective of whether the consumer is a person or a business organization. Apache Spark serves as the uniting layer that the bank employs so that it gets a combined picture of the customer. Banks can mechanize analytics by using machine learning having the assistance of Apache Spark. It’s accomplished by obtaining the information via every repository for the consumers. By this, the data hurried together into just one file, which is then passed on to the marketing department.
3. Apache Hive in the healthcare sector
With the assistance of Apache Hive, the massive data which are generated in the healthcare sector are handled and evaluated. Hive is used in the healthcare business to generate innovations that are determined via data and to progress the quality of treatment offered to patients. These applications comprise the management of electronic health archives, prognostic modeling for disease eruptions, customized medication, medical picture analytics, and distant surveillance of patients. In addition to this, it includes several case studies that illustrate the impact that Spark has had on reducing the number of patients who need readmission to the hospital, recognizing sepsis at an earlier stage, improving cancer investigation and treatment, and accelerating the development of new drugs.
4. Enhancing marketing policies via Apache Hive in the retail sector
When the retail industry is increasing, towards in opposition is indispensable. The finest way to get a modest edge is by leveraging the control of big data analytics. Apache Hive is a data warehousing and SQL-like query language software that has come as a beneficial tool for improving advertising policies in the retail sector.
As a consequence of this, retail establishments saw a significant increase in the amount of data they collected, which made it difficult for store owners to evaluate the data using conventional business intelligence equipment. Merchants may get a complete perspective of their consumers' preferences, habits, and buying patterns by combining data from different sources, like sales transactions, customer demographics, internet conversations, and social media involvement. This allows merchants to better serve their clients.
Performance Optimization Tips

Image source: https://machinelearninggeek.com/apache-hive-hands-0n/
1 Avoid locking of tables
It is tremendously significant to ensure that the tables are getting used in all the Hive queries as sources cannot be applied by additional procedures. This can give barring of the board and the query could stop for the unidentified time.
2 Use the Hive performance TEZ
While completing Hive queries, TEZ completing engine is the favored selection as it removes superfluous disk access. It creates data via disk once, functions calculations, and offers productivity, by saving us via numerous disk traversals.
3. Hive Partitioning
Division of the Hive Using Hive Optimization Techniques, Hive accesses all of the data contained inside the directory without splitting it. Not only that, but it also attaches the query filters to it. Because every piece of data has to be read, this process is both time-consuming and costly.
4. Leverage partitions and bucketing
To get the most out of dividers and grouping, it is very necessary to choose the dividing and bucketing sections with great care. A perfect scenario would be for such columns to have a large cardinality which indicates that they contain a significant number of unique values.
5. Optimizing data formats
In Apache Hive, partitioning data is an essential strategy for optimizing the speed at which queries are executed. You may dramatically increase the efficiency of your queries and minimize the amount of time it takes to run them if you divide your dataset into smaller fragments that are easier to handle depending on certain criteria.
Comparison with Other Data Processing Tools:
Apache Hive is quite appropriate for multifarious inquiries and ad hoc examination, as compared to HBase and traditional relational databases which is more suitable for real-time queries on huge datasets. At its core, Apache Spark is intended to use data processing tasks, allowing users to route and examine huge data. Spark even offers an extensive variety of libraries and APIs that support countless data processing jobs.
With the help of Apache Hive, we can assist by creating the necessary SQL queries on the database to retrieve the data easily. Contact us today!
When to use Apache Hive?
The usage of Apache Hive is recommended for situations in which developers do not want to develop complex MapReduce software and when there are needs for data warehousing solutions. On the other hand, Apache Spark services may be used to tackle any difficulties.
When to use HBase?
When it comes to real-time analytics, Hadoop is not the ideal big data framework. This is the point at which HBase may be used, specifically for real-time data querying.
After doing an in-depth comparison of Apache Hive, Spark, HBase, and Relational Databases, it has become abundantly clear that each of these tools contains distinctive capabilities and features that are tailored to meet the specific requirements of various data processing tasks.
Integration with Data Visualization Tools
1. By integrating Apache Hive with Tableau, Power BI, and Apache Superset, enterprises may have access to a wide range of valuable data insights. By integrating the robust data processing abilities of Apache Hive with the user-friendly graphical capabilities offered by these widely-used tools, organizations may get deeper knowledge and make better-informed choices.
2. An advantage of combining is the capability to rapidly and effectively analyze and display huge quantities of data. Apache Hive enables enterprises to efficiently manage large information and execute intricate queries by using its distributed processing platform. Consequently, enterprises may use the whole capabilities of their extensive data resources without sacrificing speed.
3. Tableau, Power BI, and Apache Super Set provide intuitive interfaces and powerful visualization features. These technologies empower users to generate interactive dashboards, accounts, and visualizations that promote comprehension and communication of intricate data insights. By incorporating such visualization tools into Apache Hive, enterprises can effortlessly establish a connection with their data sources in Hive and convert unprocessed data into relevant visual representations that facilitate useful conclusions.
4. By enabling connectivity to Hive tables, customers can effortlessly investigate and scrutinize data using the well-known dashboards of these tools. Users may use the sophisticated querying features of Hive to execute intricate data manipulations and computations, and then display the results in all three.
5. In addition, the integration of Apache Hive with various visualization tools enhances information management and safety. Apache Hive has strong security capabilities, such as authorization, login, and encoding that may be used when viewing Hive data via Tableau, Power BI, or Apache Superset. This guarantees the preservation of confidential information and restricts its release to approved people only.
Security Features and Best Practices:
In the present landscape of digital, data security is very prominent. As companies take care of huge data, safeguarding the privacy, honesty, and obtainability of these data is quite vital. This is a fact for the Apache Hive, an influential data warehousing and analysis tool for the Hadoop bionetwork.
- Apache Hive lets customers demand and analyze hefty sets of data kept in a Hadoop Dispersed File System (HDFS) or additional well-matched file organizations. Though, the size and understanding of data upsurges, so does the essential for best security features inside Hive.
- One of the primary reasons for highlighting security in Hive is to defend complex data through from illegal access. Data openings can get plain consequences, leading to monetary fatalities, reputation harm, and also lawful suggestions. Consequently, knowing the requirement for healthy security features has been authoritative.
- Compliance having norms and standards stipulated by the industry is still another crucial component. The government, the healthcare industry, and the financial sector are just a few of the areas that have severe rules surrounding the privacy and security of data. Through the implementation of stringent security measures in Hive, enterprises can guarantee compliance with these standards and successfully protect their data.
- Control and responsibility over the access to and manipulation of data are also provided by robust security mechanisms. Fine-grained access controls allow companies to set and enforce user rights based on roles, groups, or particular data items. These functions may be performed by the organization. In this way, it is possible to prevent unauthorized users from accessing sensitive data and ensure that only authorized workers can perform certain activities on the data.
- In addition, safeguarding Hive protects against attacks that originate from inside the organization. When workers with valid access credentials misuse or abuse data, it is not commonplace for firms to face insider threats. This kind of danger is becoming more widespread. Strong security procedures, such as auditing and monitoring, make it possible for enterprises to monitor and track the activity of their users, identify any irregularities, and take the necessary precautions to reduce any dangers.
Best practices for securing sensitive data with data protection regulations
1. Conduct a Data Discovery Process
Identifying the data that is already there, determining how much of it is sensitive or essential to the company, and determining which data must comply with security rules is the first stage in the process of securing the data contained inside your firm.
2. Manage who has access to sensitive information
There is a requirement for different employees inside the organization to have access to different information. How come? When more individuals have access to sensitive information, there is a greater potential for data theft, loss, and/or breaches inside the organization.
3. Encrypt the Data You Have
Over the last several years, there has been an exponential growth in the number of breaches in cybersecurity, which implies that personal data is easily susceptible to assaults without any protection.
4. Set up software that helps prevent malware
If your devices are infected with malware, data that is considered sensitive may be compromised by cybercriminals. Taking precautions to ensure that you have anti-malware software installed can lessen the likelihood of being attacked by malware.
5. Training employee
In terms of data security and compliance, employees play a very important role. Training and education programs should be provided regularly to create knowledge about the best practices for protecting data privacy, security standards, and the possible consequences associated with improperly managing sensitive data.
Tips and tricks for writing efficient HiveQL queries
1. Partitioning and Bucketing
The company of data is important for query performance. If you use a star diagram or a de-normalized (preferred) data warehouse based on the firm choice, dividing helps with query presentation optimization. It becomes smoother when you get professional data warehouse consulting for this process.
2. Make use of proper file formats
It is essential to make use of the right file formats to guarantee the easy interchange of digital information and interoperability between them. This is done to guarantee that consumers are unable to access, edit, or duplicate the source code and then resell it as their product.
3. De-normalizing data
In the realm of database administration, de-normalizing data is an essential procedure that entails reorganizing data to enhance performance and simplify complicated queries.
4. Utilize the Hive Cost Based Optimizer (CBO) tool
An optimizer that is based on costs is provided by Apache Hive to increase performance. It does this by analyzing the query cost, enabling it to produce effective deployment strategies such as how to arrange arrives, the sort of join to do, the level of paralleling, and so on.
5. optimize table format
The overall efficacy and readability of a table may be significantly improved only by optimizing the format of the table. Hive supports a variety of table formats, including ORC, and Avro, all of which are suited for a particular use.
Community Resources and Support
1. Stack Exchange
Several mechanisms are indispensable to a flourishing big data bionetwork. Stack Exchange uses a popular community question-and-answer platform and it hosts several sites, including Stack Overflow and Server Fault.
2. Google Cloud Community
Google Cloud Community swarms peer-to-peer product environments and it's an amazing resource to get Apache hive-related answers. You can make a post to the best conversation environment, and an additional community associate will get back to your question. You can also participate in this where there is ask me anything.
Explore the future developments and roadmap of Apache Hive
- Apache Hive is extensively used by enterprises across many sectors, including e-commerce giants and social media platforms, because of its flexibility and ability to integrate with current SQL-based tools and frameworks. Nevertheless, despite its triumph, Hive still has some obstacles that must be resolved for it to maintain its position as a leader in big data analytics.
- Moreover, the changing data environment and rising technologies provide further difficulties for Hive. In light of the increasing prevalence of streamed data and the demand for immediate data analysis, Hive must adjust and adopt fresh techniques for data input and processing. By incorporating Hive with Apache Kafka, a widely used distributed broadcasting system, and investigating possibilities for integrating frameworks for machine learning such as Apache Spark, Hive can ensure its continued relevance in the swiftly developing big data environment.
- An important development is the implementation of Hive LLAP (Live Long and Process).
- Another significant advancement is the integration of Hive with Apache Tez, a powerful information processing framework known for its excellent performance. Tez offers a very effective running engine for Hive, enhancing query processing and optimizing resource consumption.
- In addition, Hive has prioritized improving its integration with SQL and growing its strengths in SQL. Hive is being more resilient and dependable option for multi-row modifications and deletes with the implementation of Hive ACID (Atomicity, Integrity, Separation, and Persistence) procedures. This enhancement makes Hive ideal for scenarios that include modifying information operations.
Upcoming enhancements
- The newest version of Apache Hive presents better-quality support for indexing, letting people make indexes on Hive boards for quicker data recovery.
- ACID dealings in Hive get a new phase of dependability and data integrity to the policy.
- Apache Hive is a dynamic project that is well-regarded within the big data ecosystem. Hive is actively enhancing its capabilities in analytics, reporting, and bilateral queries, while the community is making efforts to enhance support and address many additional features and use cases.
- There are the most recent and advanced features and optimizations which is implemented in this project for 2023. The benchmarks include several aspects like as LLAP, Apache Druid's realized views and integrating, management of workloads, ACID enhancements, use of Hive in cloud environments, and performance enhancements.
Some testimonials or quotes with experiences with Apache Hive
1. Instagram
As the Instagram industry grew exponentially, and with that the data also grew. They were hostile to professional work and examined such data to get actionable insights. The current infrastructure showed insufficient information that led to delays, disorganization, and wasted chances. Apache Hive is an amazing software that can query and check data. Its simplicity of use and best performance in managing it created it to be the amazing ETL testing Solution. With the help of applying Apache Hive, Instagram could rationalize its data handing outflow of work and meaningfully enhance its analysis competencies. The platform's capability to function with organized and semi-structured data made it simple for its team to excerpt expressive understandings through an extensive variety of data sources.
2. Amazon
One such story comes from an important Amazon that was struggling to examine and practice vast amounts of customer data appropriately. With an increasing customer base and a growing capacity for dealing, their current database organization structure was powerless to keep up with the demands. As a result, there were delays in producing valuable insights, which impeded their capacity to make choices based on data. In response to the requirement for improved efficiency, the organization opted to use Apache Hive.
3. Flipkart
Flipkart ventured into the realm of ecommerce similarly to Amazon, by first focusing on the sale of books. Subsequently, it has swiftly grown to include several additional retail sectors inside its domain. It is renowned in the ecommerce industry for offering very cost-effective electronic products such as mobile phones and home appliances. The important nature of Hive lies in its capacity to effectively manage data that is structured as well as unstructured originating from many sources. The firm successfully integrated client records, outcomes, and other pertinent data to get a comprehensive perspective of the data profile.
Streaming Analytics with Hive
Many industries demand data streaming in real-time and Apache Hive is the oldest platform to process it. Getting authentic analytics is complex as social media, virtual gaming, or IoT constantly spew data. Apache Hive is one of the best platforms for real-time/streaming analytics. Being an open-source software, it is easy to manage continuous data sets emerging in real-time. It is an SQL-based declarative language that allows developers to add their scripts when required. It also offers a core hub for centralized data. With Schema-on-read it is ideally suited for queries and diverse data storage types.
Keeping implementation concerns in mind, it is possible to process streaming data by using Hive. The concerns relate to reducing latency, NameNode reaching capacity, and maximizing per-thread throughput. This design can be applied with a simple example. Ten columns of data can be serialized at the 1row/100ms. Check the configuration capacity to support Hive Streaming for making the tables. The Hive table can be supported in the ORC format. The table can be specific, for example, ‘transactional’ equals to be true. When a property is well-defined the Hive streaming feature is supported to produce the best results. The same can be added to other buckets like customer information with Schema.
Conclusion
Apache Hive is liked by Business Analyst, Testers, Data Analyst & even Developers because of its flexibility and easiness to run SQL-Like query on top of Big Data solution companies.
However, there are other ETL tools coming into the marketplace everyday such as Presto, Impala but Hive has already secured its place and is well used across the industry.

