

Delta Lake rules to perform operations
Delta Lake provides a feature which validates schema and throws an exception if the schema is not matched. Delta Lake uses the below rules to check if the schema of the Dataframe matches with delta table to perform operations:
- If we are trying to write new columns to a delta table which doesn't exist before, it throws an exception. If we are missing some values while writing, it fills them with null values.
- When we are writing to a delta table from a dataframe, if the columns datatype is not matched an exception is thrown.
- Delta table columns are case insensitive. If the columns contain the same letters it throws an error.
Schema Validation in Spark without Delta Lake
As you might know, Apache spark services on schema on read which means it doesn’t check for schema validation while writing to a target location. But when we try to read from the target location it throws an error.
Delta Lake Operations for Schema Validation
Delta lake allows users to merge schema. If there are columns in the DataFrame not present in the delta table, an exception is raised. If new columns are added due to change in requirement, we can add those columns to the target delta table using the mergeSchema option provided by Delta Lake.
Now let us see and understand how it works in Spark without delta lake. Let us create a dataframe and write it to a parquet file and later change the data type of the column and write to a same location and see how it works.
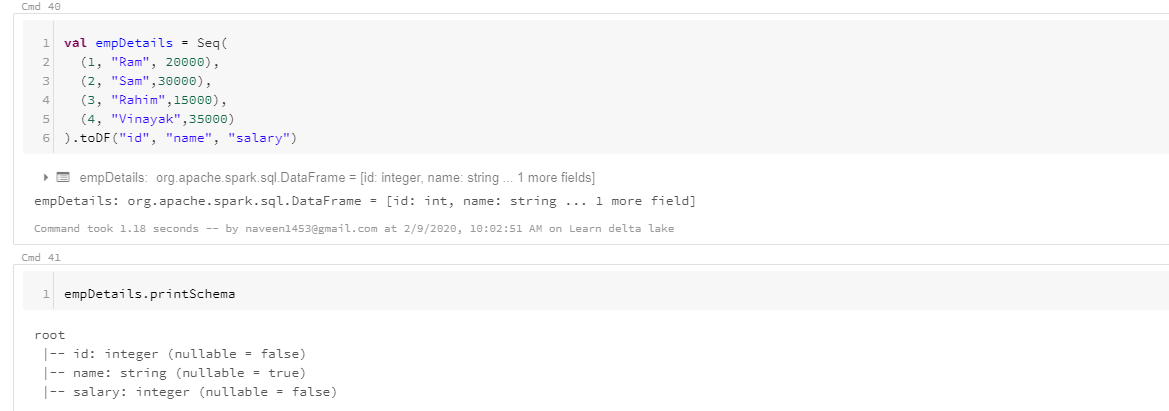
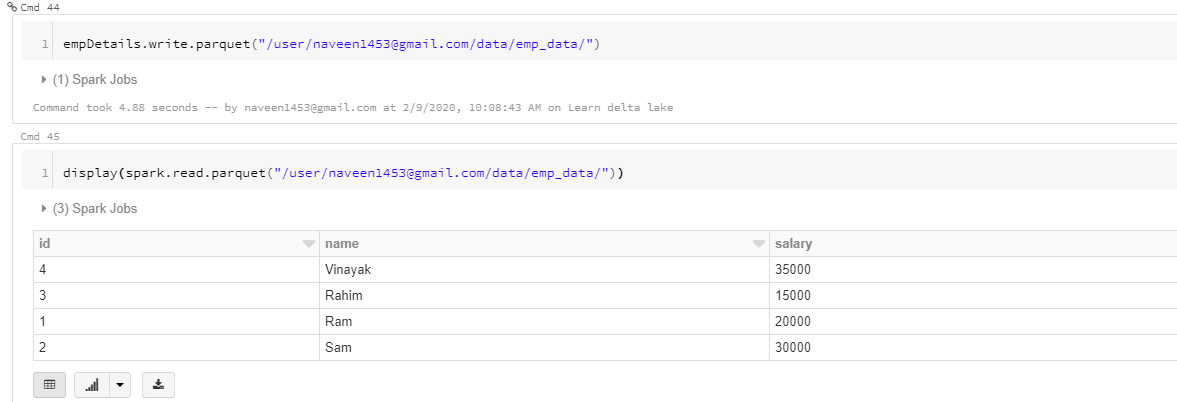
If you see the schema of the dataframe, we have salary data type as integer. Let’s write it to parquet file and read that data again and display it.
Approach us and avail our expert services in this regard. We specialize in validating schema in Delta Lake and get the desired output.
Now let's change that data type of the salary to double type and write it to the same location and see what happens.
Now when we write to the same location we don’t get any errors, that is because Spark works on schema on read, it doesn’t validate schema while writing.

But when we read data, it throws an error. Our data is now corrupted and it causes serious damage.

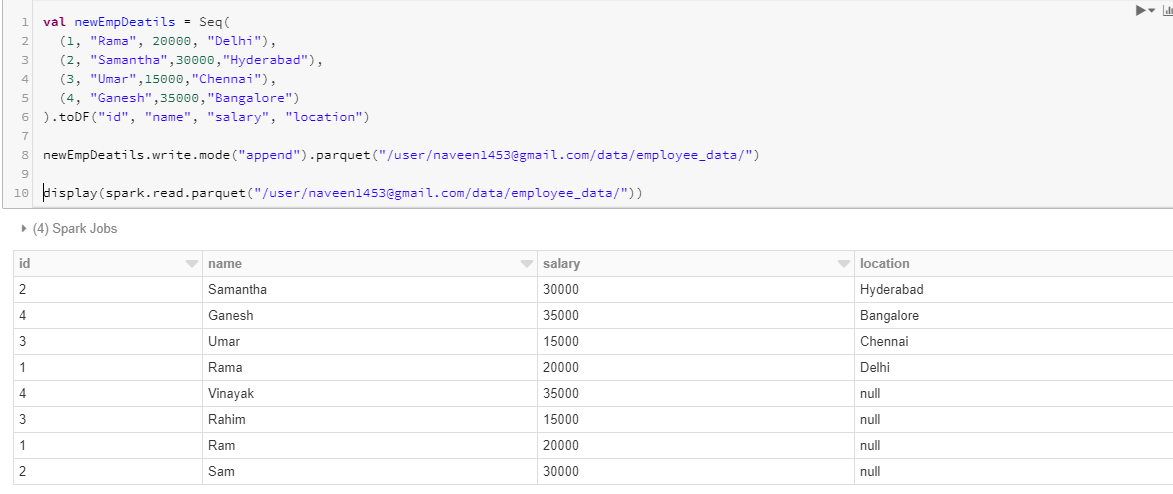
Now again let’s create a new dataframe and write this to a target location and then try to write more columns to the same target location and see what happens.
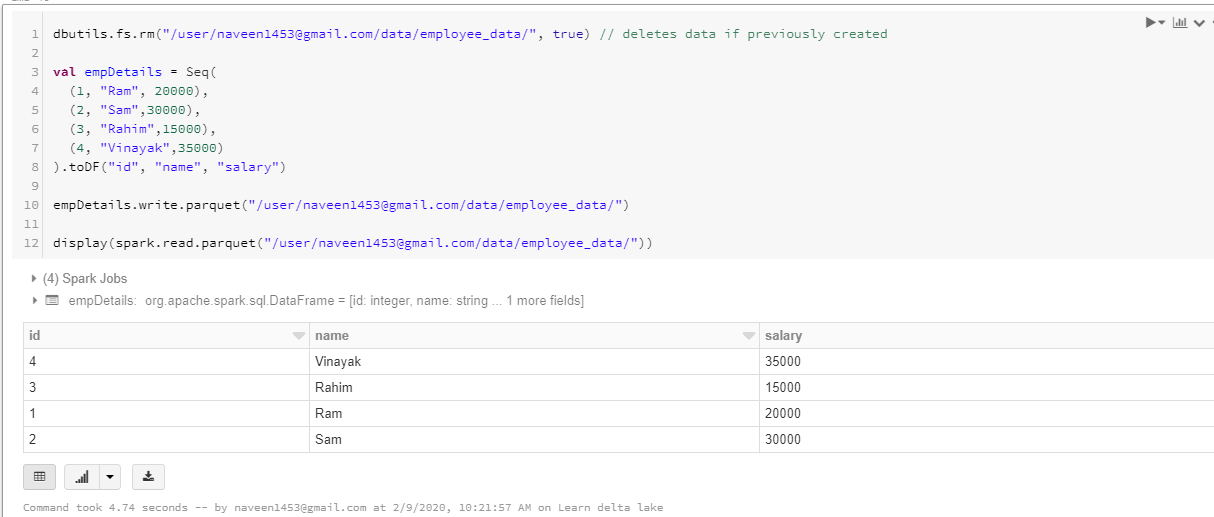
Now let’s add one more column named “location” and write it to the same location. If you see below, the new column is just added and for those previous records where there was no data for the location column, it is set to null. It didn’t check for schema validation and doesn’t have strict rules on schema. It clearly shows us that Spark doesn’t enforce schema while writing. It can corrupt our data and can cause problems.
Now let’s do the same operations in delta lake and see how strictly it checks for schema validation before writing data to the delta table.
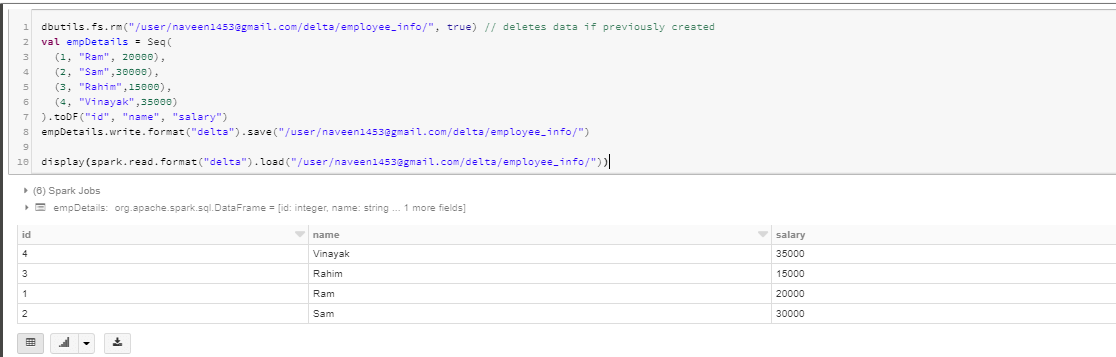
First let’s check how it handles data type schema validation. I am trying to write a salary of type integer.
Now let me see what happens when I try to add the salary of the float data type.

You can see it raises an exception, Failed to merge incompatible data types IntegerType and DoubleType; It enforces schema and doesn’t allow writing data which is not compatible.
Now let us see what happens when we have more columns in the dataframe than that of the delta table we are trying to write to.
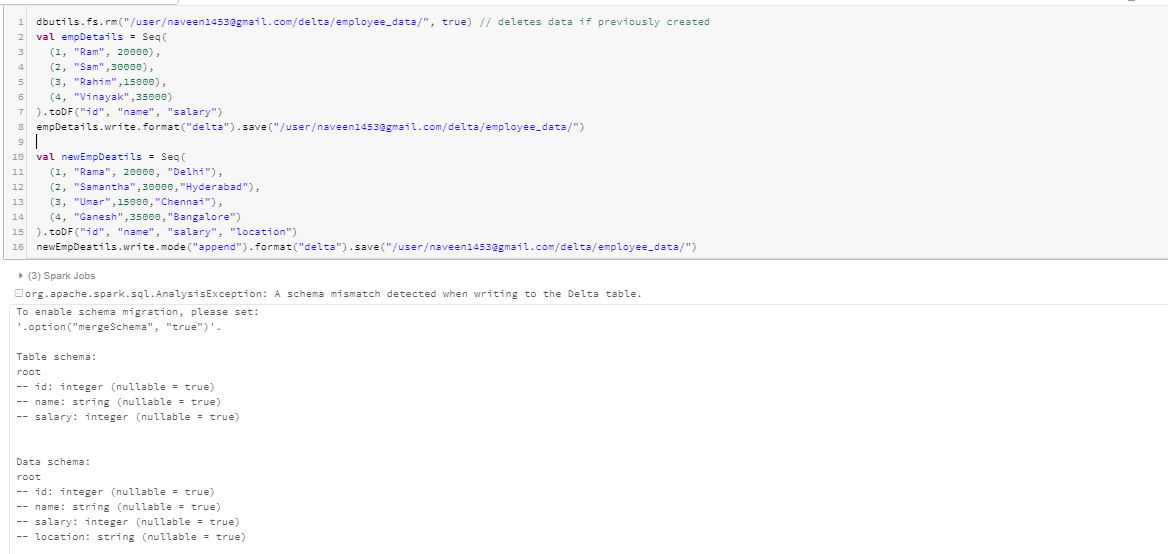
You can see above that exception is raised and data is not written to the target folder because delta enforces schema.
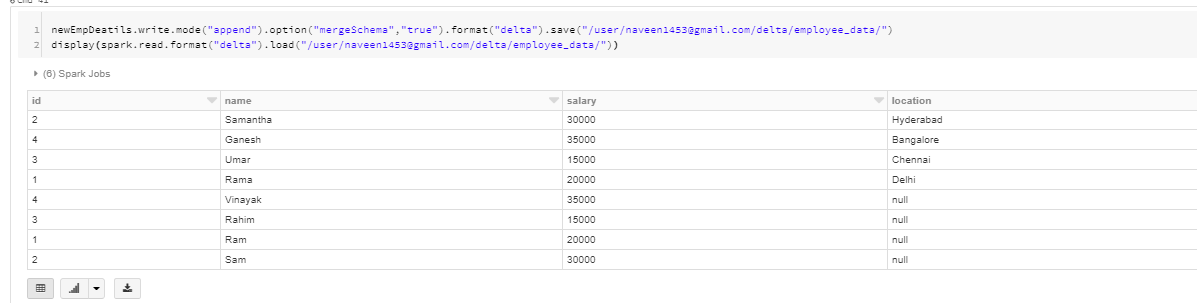
But If this is a requirement in design and if we have added this column then all we have to do is provide the option '("mergeSchema", "true")' while writing data.
Find out more articles related to big data analytics and consulting solutions below. Happy learning!

