

YARN is an open source Apache project that stands for “Yet Another Resource Negotiator”. It is a Hadoop cluster manager that is responsible for allocating resources (such as cpu, memory, disk and network), for scheduling & monitoring jobs across the Hadoop cluster.
Earlier versions of Hadoop only supported the running of MapReduce jobs on the Hadoop cluster; however, the advent of YARN has also made it possible to run other big data solutions frameworks such as Spark, Flink, Samza and many more on the Hadoop Cluster.
YARN supports different types of workloads such as stream processing, batch processing, graph processing and iterative processing.
What is YARN Architecture?
Apache YARN consists of two main components: Resource Manager and Node Manager. Resource Manager is one per cluster whereas Node Manager daemon runs on all worker nodes.
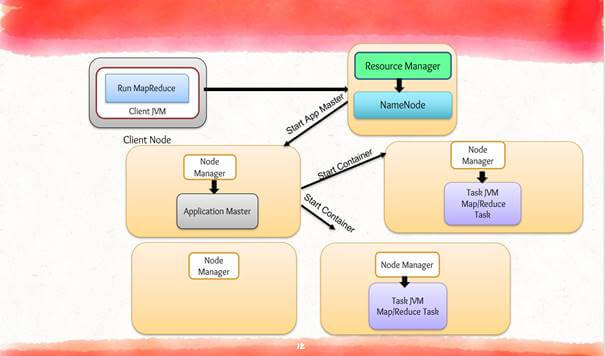
Resource Manager is a daemon responsible for allocating resources in the cluster. It has two main components, namely the Scheduler and the Applications Manager. The Scheduler is responsible for scheduling the applications across the cluster based on memory and CPU requirements. There is only one Resource Manager per cluster.
Professional data warehouse consulting is often required at this stage to tune scheduler settings, ensuring that background tasks don't sideline high-priority analytical jobs.
Application Manager accepts jobs & creates specific Application Masters and restarts them in case of failures.
Node Manager is a daemon that runs on all worker nodes and manages resources at machine level. Node manager defines the resources that are available on node and keeps tracks of usage. It also tracks the health of nodes and if found unhealthy communicate it to the resource manager. Node Manager communicates with the resource manager to send regular reports about report usage and coordinate with the application master to spawn JVM for task execution.
The Application Master is responsible for handling the entire life cycle of Applications starting with resource negotiation, tracking and monitoring job status.
Running big data solutions on the Hadoop cluster can be challenging. Contact us to know more about an open source called YARN that helps you efficiently allocate resources across the Hadoop cluster.
How YARN Supports Frameworks?
YARN is not just limited to Hadoop MapReduce; it can be used to run one of the most promising big data consulting services frameworks such as Spark, Flink, Samza and many more. Below list represents all frameworks that can currently run on top of YARN.
YARN SCHEDULER
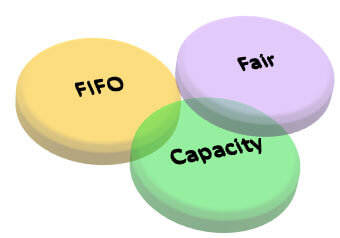
YARN supports three scheduling policies namely FIFO, Capacity and Fair Scheduling that decides how the incoming jobs will be scheduled or prioritized.
FIFO Scheduler:
In FIFO Scheduler policy, applications are served on a “First in First out” basis but this policy can lead to job starvations if the cluster is shared among multiple users. So, this policy is not optimal in shared clusters. By Default, YARN is always set to FIFO policy.
Capacity Scheduler:
In Capacity Scheduler, different organizations share their Hadoop cluster to maximize utilization of the cluster. Though organizations are sharing their cluster, Capacity Schedulers make sure that each organization is getting their required capacity.
Capacity Scheduler provides capacity guarantees, elasticity, resource-based scheduling, priority scheduling, multi-tenancy, all of which are useful in a data warehousing environment. We have to set the property below in the conf/yarn-site.xml file to enable Capacity Scheduler in YARN.
| property | value |
|---|---|
| yarn.resourcemanager.scheduler.class | org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler |
Fair Scheduler:
Fair Scheduling policy makes sure that all running jobs get roughly equal shares of resources (memory or cpu). Jobs are divided into queues and resources are shared equally among those queues. It always guarantees a minimum share to the queue and if the queue is empty, excess resources are distributed for jobs running in other queues. We can also define a set of rules that get applied to submitted applications so that applications land into appropriate queues for further processing.
| property | value |
|---|---|
| yarn.resourcemanager.scheduler.class | org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler |
Reservation System
Users can reserve some resources in YARN using a reservation system so that critical applications always get resources on time. We can mark any leaf queue as a reservation queue in Fair & Capacity Scheduler (fair-scheduler.xml/capacity-scheduler.xml). Let’s see how it works.
The user submits the reservation creation request and receives a reservation Id. In the next step, users send the reservation request along with a reservation id and a ReservationAgent called as GREE will create a reservation in the Plan (Plan is a data structure that maintains & tracks all reservations).
In future whenever a user applies with reservation id, scheduler will make sure that the application gets the reserved resources. However, when resources are not in use can be used for execution of other applications as well.
High Availability
Earlier to Hadoop 2.4, Yarn Manager was the single point of failure in the YARN cluster. However, after Hadoop 2.4 Resource Manager works in Active/StandBy mode to provide fault tolerance and high availability.
Standby Resource Manager always keeps track of all changes that are happening in active Resource Manager and can take its place in case of failures. The Resource Manager closely works with the zookeeper to write its state and to decide which Resource Manager should be active in case of failures.
Fail-over Transition from active mode to standby mode can either happen manually or automatically. Manual failover transmission fa can be done by administrator by using “yarn rmadmin” cli whereas in automatic failover transmission zookeeper daemon is used.
Yarn Federation
Yarn Federation is a technique to club smaller YARN clusters together to appear as one large cluster. Applications running on federated clusters can get scheduled on any of the nodes of the sub cluster. There will be multiple Resource Managers each per cluster. Such architecture provides a lot more flexibility and scalability as a separate Resource Manager will be handling part of the cluster thus increasing the overall performance of scheduling and monitoring.
YARN Versus Mesos
Apache Mesos is another well-known resource manager in the market. There are few significant differences between the both.
| YARN is written in Java | Mesos is written in C++ |
|---|---|
| By default, in YARN is based on memory scheduling only. | By default, Apache Mesos has memory and cpu scheduling |
| Apache YARN is a monolithic scheduler which means it follow a single step to schedule & deploy the job | Apache Mesos is a non-monolithic follows the two-step process to schedule & deploy. |
| Apache Yarn is less scalable. | Apache Mesos is more scalable |
Conclusion
Undoubtedly, YARN is a robust, flexible, configurable extensible resource management engine that supports more than 15 big data frameworks. It allows external system to leverage Hadoop Distributed file system. It is highly in demand and used widely across the industry.

