

Introduction
If the requirement is to host very large tables and we want to access then randomly and in real-time HBase is a great choice which can fulfill our requirement. But what if the completion time of requirement is very low and we don’t have sql-familiar developers to create code in HBase. Here comes the importance and use case of hire apache spark developers wherein we can write SQL queries over HBase tables and access our data.
Introducing the fetching process of Hbase Table data in Apache Phoenix
In this tutorial, our developer has tried to explain the fetching process of Hbase Table data in Apache Phoenix and discovered the relation of Big Data Services with it. We can integrate HBase with Phoenix to access our HBase tables and can achieve the same results without even learning HBase code syntax. This is a great use case for someone who is familiar with sql but needs time to learn HBase as they will be creating standard JDBC API’s to access the data.
Hence, in this case they don’t need to learn HBase and don’t need to create HBase API. We can think of it as a layer between our application and HBase. And that’s why HBase and Phoenix are called birds of a feather. But this raises the question that if that’s the case it can slow things down as we are applying something extra to already existing architecture.
We can assist you by writing required SQL queries on the HBASE table using Apache Phoenix which will make access to data easy.
Phoenix or HBase
Phoenix is faster than HBase and it gives better performance than HBase. Phoenix is lightning faster than Hive. Phoenix has its limitations too and if the requirement of batch processing Hive is better than Phoenix. Also many times it can cause issues with the Hbase metastore. Also few joins like full outer join and cross join are not fully supported.

Installation:
We can Install Phoenix Jar in our Hadoop environment in two ways:
- If the Phoenix jar is already present in one of the old nodes.
- If you are doing a fresh installation
We will be discussing both the scenarios in detail below:
1) If the Phoenix Jar is already present in one of the old nodes: - You can check if Phoenix Jar is already present in one of the old nodes or not. If yes then follow below process to copy it from any of old data node to newly data node:-
Example:
OR
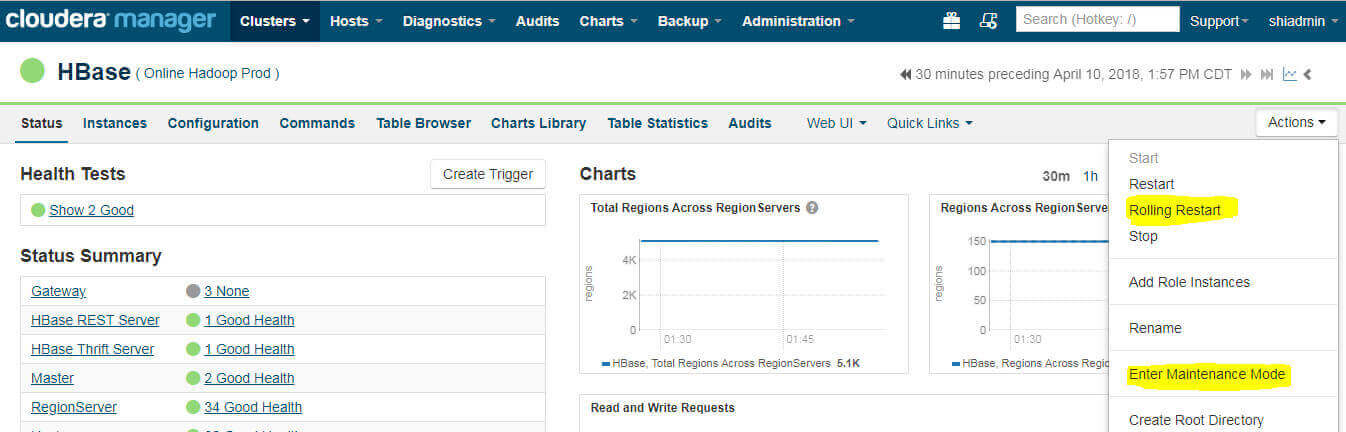
1. Once Copying is done. Restart the Hbase service. Follow below steps to perform Hbase Restart:-
Login to http://dwhadooplm3004p.prod.ch3.s.com:7180/cmf/login
Go to hbase → action → Enter maintenance mode → restart
Issues using Phoenix:-
Issue1:-
Sometimes when we search for same table in Phoenix that we have already created in HBase then Issue is we can’t able to see it. It’s actually a limitation in Phoenix wherein it will not automatically takes the data from HBase metastore.
To resolve such kind of issues we need to create same name table in phoenix. Once it’s done it will automatically pick the data from the HBase metastore and show the same into Phoenix table.
Issue2:-
Establish connection between newly added Nodes and Application Job server:-
This scenario is related with “connection timeout error” during phoenix job run. This mainly happened because a PCI server (ucapp301p.prod.ch3.s.com) is trying to make a connection with newly added nodes without a firewall rule in place for the connection. To find out whether server PCI servers or not, try below steps:-
For physical servers, they will have an IP address of 10.235.100.x or 10.236.100.x.
For virtual servers, it’s tricky and the application team will know (SHOULD know) if their servers are behind the vArmour firewall.
You can run below command to check whether server is able to make connection or not:-
When a table is made in Phoenix, and the data is loaded in it, then that data should replicate in the HBase under the table. Although, it will have a similar name. Although, if you try the opposite, that may not be possible. You would have to probably, manually map the complete Phoenix table with the specific HBase table.
This tutorial is proposed by the the Big Data Services provider from India to help you learn about fetching Hbase Table data in Apache Phoenix.

